title: "AI Consulting: Client-Ready B2B Package in 4 Hours" slug: client-ready-b2b-package seo_keyword: "AI consulting" meta_description: "AI consulting delivery: stop delivering strategy decks. Extract a working knowledge system in 4 hours - 15 folders, 10-18 skills, populated with client data." og_description: "Strategy decks gather dust. I extract a working B2B knowledge system in 4 hours -- 15 folders, 10-18 AI skills, client data populated, persona-routed onboarding. 5 phases, 49 iterations of lessons learned." cluster: ai-consulting author: Victor status: published published_date: 2026-03-25 read_time_minutes: 8 description: "AI Consulting: Client-Ready B2B Package in 4 Hours" domain: steepworks type: article updated: 2026-03-25
How I Extract a Client-Ready B2B Package from My Knowledge OS in 4 Hours
I used to deliver strategy decks. Sixty pages, custom research, clear recommendations. Three months later, the deck lived in a Dropbox folder nobody opened.
The thinking was solid. The format was the problem. This is what delivery looks like when you stop building documents and start building systems -- and what it actually takes to extract a client-ready B2B knowledge package in a single working day.
The "4 hours" is the extraction-and-packaging phase. Before that: ~90 minutes of research and a client intake call. After: a 30-minute handoff session. Total wall-clock time from first contact to a working system on the client's machine: about one working day. That's still a different planet from the 2-4 weeks most custom engagements require for setup alone. But the honest number matters more than the impressive one.
Why Most Deliverables Gather Dust
Static deliverables decay the moment they're delivered. The market shifts. The team changes. The context that made a recommendation relevant expires. A deck can't update itself when the competitive landscape moves.
McKinsey solved this years ago with "knowledge objects" -- modular, reusable components designed for extraction across engagements. Ernst & Young built "PowerPacks" -- pre-built analysis modules that deploy without starting from scratch. Bloomfire's analysis documents how these firms turned knowledge extraction into a core process. But those systems require dedicated KM teams, enterprise infrastructure, and budgets impossible for a solo operator or small firm.
The productized consulting movement has been building momentum. Consulting Success calls it "shifting from selling time to packaging expertise." The economics are compelling: predictable revenue, lower acquisition costs, scalable capacity. But most productization advice stops at pricing and scope. Nobody shows the extraction mechanism -- how you pull a client-ready package out of your knowledge system in hours instead of weeks.
My shift wasn't incremental. Instead of documents, I started delivering a working system -- a knowledge repository with embedded AI skills the client's team operates on day one. The deliverable isn't a recommendation. It's a tool that generates recommendations tailored to the client's data, and improves with use.
The Architecture That Makes 4-Hour Extraction Possible
The speed comes from the source architecture, not from rushing. Four hours is possible because the system was designed for extraction from day one.
Three patterns make it work.
Pattern 1: Reference-Not-Copy
AI skills -- workflow modules handling prospect research, meeting prep, competitive analysis -- don't contain company context inline. They reference a single canonical source file. Update that source, every skill sees the change.
Think shared Google Doc versus 10 copies in 10 folders. When I update the shared doc, everyone who links to it sees the change. Copy the doc into 10 folders, and versions drift within a week. Someone updates positioning in copy #3 but not copies #1, #5, #9. By month two, four different versions of company context, nobody sure which is current.
One deployment used a single shared context file -- 194 lines -- serving 10 skills and 3 commands. One file update propagated to everything.
For extraction: you replace ONE shared context file. Every skill inherits the new context. The alternative -- customizing each skill individually -- is what makes template-based consulting take weeks.
Pattern 2: Foundation Documents as a Canonical Layer
Five summary documents form the base: positioning, company overview, ICP model, buyer personas, brand voice.
That's it. The 80/20 principle in productized consulting is well documented, but the ratio is closer to 95/5 when foundation documents are well-structured. The remaining 5% -- industry nuance, team preferences, edge-case workflows -- is where the intake conversation earns its time.
These are summaries, not exhaustive references. Detail lives underneath in domain folders. The information pyramid: AI reads the summary first, gets 80% of context in 20% of reading time, goes deeper only when needed. I described the full folder architecture in Building a Personal Knowledge OS: 4,700 Files Deep.
Pattern 3: Behavioral Rules by File Path
Different folders carry different behavioral contracts. Finance file triggers confidentiality rules. Customer research file activates evidence standards. Consulting engagement file loads client anonymization.
The extraction inherits safety behavior automatically. No checklist to remember "don't expose client names" -- the system enforces it based on which files are open. For clients, these rules get customized to their industry's compliance, data sensitivity, and workflow preferences.
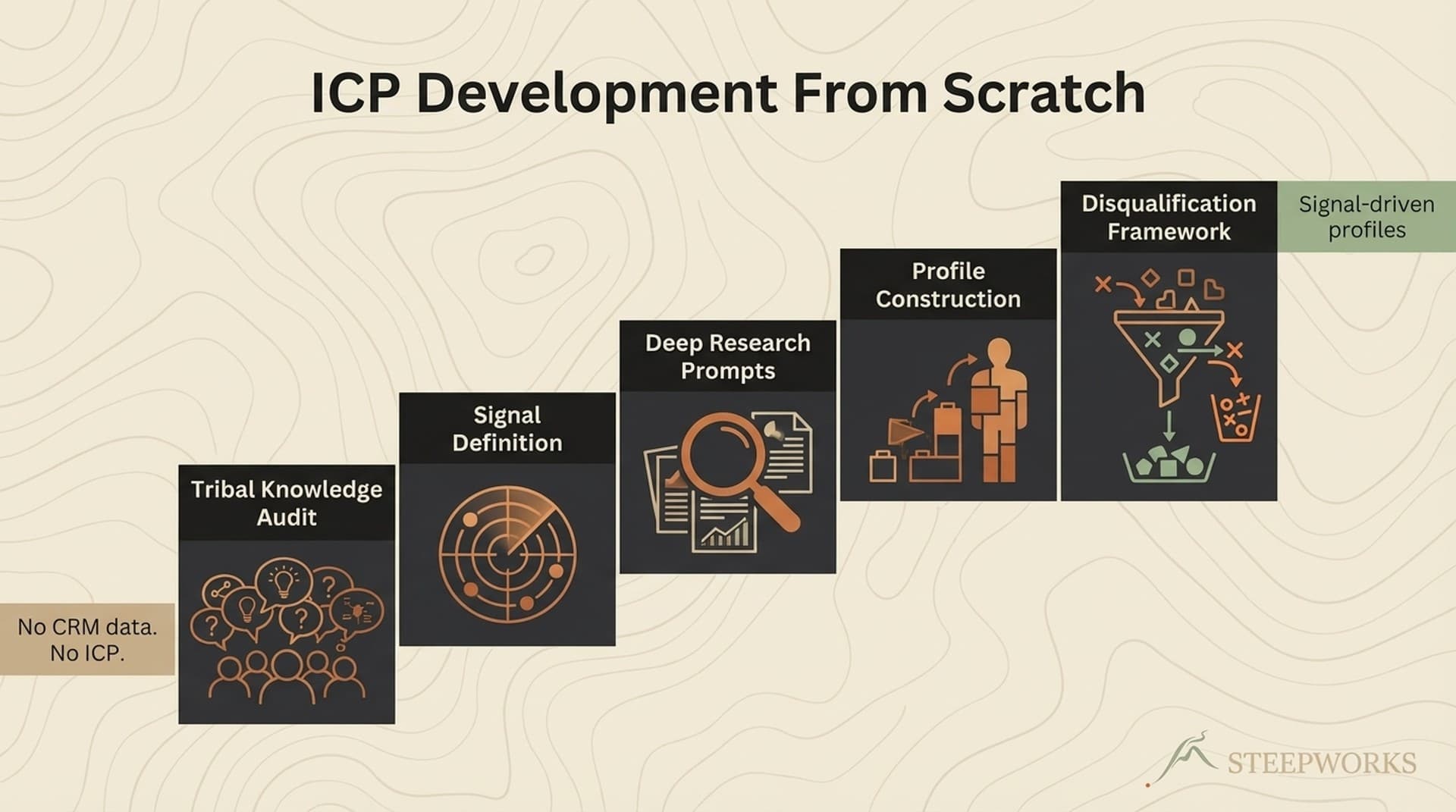
The 4-Hour Extraction: Phase by Phase
Phase 1: Research and Intake (Pre-Extraction, ~90 Minutes)
Automated research (45-60 min): Structured prompts run against public data -- website, LinkedIn, press releases, case studies. Designed to extract facts (revenue range, employee count, named competitors, product names), not opinions. Output feeds the intake questionnaire.
Critical principle: upstream/downstream separation. Research prompts describe reality. They don't recommend. "Company X has 3 named competitors in the embedded controls space" is upstream. "Company X should position against Competitor A" is downstream. Keeping them separate prevents bias from contaminating foundation documents.
Client intake call (30-45 min): Fills what research can't reach. How does the client describe what they do? Who's the primary system user? What's their tool stack? What does the team struggle with most?
Phase 2: Context Injection (45-60 Minutes)
Populate the shared context file from research and intake. Then populate the 5 foundation documents: positioning, company overview, ICP model, personas (flagged as draft), brand voice.
Human judgment needed in three areas. Positioning: does the one-liner sound like how the client talks, or how an AI summarized their About page? Personas: realistic, or needing client correction? Voice: right tone for their industry?
Quality marker: grep for remaining template placeholders. Zero should remain.
Phase 3: Stripping and Anonymization (45 Minutes)
When you extract from a personal knowledge system, you carry artifacts: other client references, personal project names, internal paths, even financial data in adjacent folders.
What gets stripped: Other client names, personal domain folders, internal system references, session logs, non-client example content.
What stays: Folder structure and rules (the product), skill definitions, populated foundation documents, onboarding flow, automation scripts adapted to the client's stack.
An artifact sweep via grep catches ~80% of contamination. The remaining 20% requires judgment. Is this example useful despite referencing a different industry? Is this framework generic enough to keep? (implementation consulting)
A lesson from a live deployment: template files shipped with previous engagement examples -- specific names, metrics, competitive references irrelevant to the current client. The sweep caught most, but three slipped through into skills outside the standard sweep pattern. Now the sweep covers all skill files. That mistake cost 30 minutes during a handoff. (See also: knowledge os)
Phase 4: Testing with Synthetic Data (30 Minutes)
Create a synthetic prospect matching the client's ICP. For an industrial company: "Director of Controls Engineering at a mid-market OEM, dealing with a controls staffing gap and an 8-week deadline." (See also: research prospect)
Run the cold-outbound skill. Does output reference the client's value proposition? Use gap messaging ("you're 3 engineers short and your deadline is in 8 weeks") instead of feature messaging? Sound industry-aware? (evaluate a consultant)
If the output sounds generic, context injection broke somewhere.
Run 2-3 more skills: meeting prep, content draft, competitive analysis. Five to eight minutes each. Not exhaustive evaluation -- checking that context injection works and stripping didn't leave gaps.
Phase 5: Quality Gate and Packaging (30 Minutes)
Zero placeholders. Zero wrong-client artifacts. Valid file paths. All skills referencing the correct shared context.
Onboarding validation: does the first-session flow match the primary user's role? If the user is a CCO, the first exercise should be a competitive battlecard, not an SDR prospecting workflow.
Package, push to VCS, verify the client can clone and access.
What the Client Gets
Not a document or slide deck. A working repository they open in Claude Code and use immediately.
- 15 organized folders covering GTM domains
- 5 populated foundation documents with their actual research data
- 10-18 AI skills pre-loaded with competitive intelligence, personas, and messaging -- each referencing the shared context automatically
- Persona-routed onboarding so the first session is productive. A CCO sees competitive battlecards. An SDR sees prospecting. A content lead sees editorial calendar.
- Behavioral rules customized to their domain
First week: Open Claude Code, run onboarding, complete a first-win exercise. By session end -- 30 to 60 minutes -- a real deliverable: prospect brief, competitive analysis, or content draft. Using their data.
Month 3: Foundation documents aren't static. Meeting notes feed customer intelligence. Outreach results refine personas. Content performance updates positioning. The system was designed to compound. Static deliverables start decaying on day one. A knowledge system starts compounding.
What Breaks (And the 15 Patterns I've Codified)
49 iterations across 3 project phases for one client. Each deployment surfaced failures. Four that matter most:
Wrong-Client Artifact Contamination
Templates shipped with previous engagement data. The grep sweep catches ~80%. Remaining 20% requires line-by-line review. I expanded the sweep to ALL skill files and maintain a running contamination pattern list -- currently 23 patterns, growing.
Shared Context Drift
Without reference-not-copy, 10+ skills each had inline context that drifted. Client A's positioning showed up in Client B's templates. Single shared context file -- 194 lines. One file to update. Drift eliminated by architecture, not discipline. Discipline fails when you're tired.
Foundation Bloat vs. Starvation
A 500-line company overview produces worse output than a 150-line summary. The AI spends attention on detail it doesn't need. Standardized on 5 documents, each under 200 lines, with depth in domain folders.
Persona-Blind Onboarding
Generic onboarding doesn't stick. A CCO needs different examples, exercises, and priority folders than an SDR. Without persona routing, first sessions confuse. Confused users don't return.
Honest limitation: 15 patterns from 2 completed deployments plus my own system. Enough for robust patterns, not universal coverage. Healthcare and financial services almost certainly surface patterns I haven't hit.
When This Doesn't Work
No positioning clarity. If the client can't articulate what they do in one sentence, extraction stalls at Phase 2. I flag it during intake and recommend a positioning exercise first.
Deeply regulated industries. Healthcare and financial services add 2-4 hours of custom rule creation. The 4-hour extraction becomes 6-8. Still faster than weeks.
Legacy tool stacks without APIs. Skills still work, but without automated data flow the system can't compound over time. Knowledge repository, not connected system.
Teams not on Claude Code. Skills and rules need porting. Doable but adds time and compatibility risk.
BCG found that companies achieving AI value at scale redesign workflows before deploying technology. Same principle. The extraction works when workflows are clear enough to embed. When they're not, the build surfaces that gap -- valuable in itself, but the scope changes from "4-hour extraction" to "discovery plus extraction."
From Deliverables to Systems
The old model: research for 2 weeks, synthesize for 1, deliver a document, walk away. Stale by month three.
The new model: extract a living system in hours. It compounds because the architecture was designed for AI agents to traverse. The client receives a tool that generates recommendations from their data and improves with use.
This is what delivery looks like when you build for the client's Monday morning, not the handoff meeting.
The reference-not-copy insight extends beyond consulting. Any team maintaining knowledge across multiple workflows faces the copy-versus-reference decision. Ten copied documents that drift apart is a maintenance problem worsening monthly. One canonical source that everything references is a system improving monthly.
The competitive advantage isn't AI tools. Anyone can prompt an AI. The advantage is architecture: knowing which context to inject, what to strip, how to test, and where extraction breaks. Forty-nine iterations taught me things no framework document could.
For the full folder architecture, memory layers, and the failures that shaped the system: Building a Personal Knowledge OS: 4,700 Files Deep.
The deliverable isn't the deck anymore. It's the system. And the system keeps working after the consultant leaves.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.