title: "AI Prompt Engineering for GTM: Build a Router" slug: 5-prompt-patterns seo_keyword: "AI prompt engineering for GTM" meta_description: "AI prompt engineering for GTM: 46 prompts audited, reasoning models broke the best ones. Build a router that classifies tasks and selects models." og_description: "I had 46 production prompts. Opus performed worse with my most structured ones. A prompt router that classifies tasks into 5 archetypes, adapts structure by model tier, and enforces quality gates." cluster: claude-code-operators author: Victor status: published published_date: 2026-03-25 read_time_minutes: 11 description: "AI Prompt Engineering for GTM: Build a Router" domain: steepworks type: article updated: 2026-03-25
Stop Writing Prompts. Build a Prompt Router.
I Had 46 Prompts. Then I Built One Skill That Made Them All References.
A year ago, my most-referenced asset was a prompt library. 46 production-tested prompts across 10 categories — sales enablement, deep research, competitive intelligence, prospecting, content production, customer intelligence. Each one was structured with phased instructions, evidence standards, scoring rubrics, and output schemas. Each one was the product of iteration — sometimes 10+ rewrites before it performed reliably (rewrites from me + OpenAI + Gemini + Claude collaborating).
The library was good. The problem was everything around it.
Which prompt do I reach for when a task crosses categories? When competitive research needs to feed into content production? When the research prompt was built for Sonnet but I'm running on Opus? I was spending more time finding and adapting prompts than using them. A 46-prompt library sounds like an asset until you realize it comes with a discovery tax — the cognitive overhead of selecting, evaluating, and adapting the right prompt for the right situation.
Then reasoning models shipped, and the discovery tax became only one of my problems.
When Opus 4.5 arrived, something contradicted most of what I'd read about AI prompt engineering for GTM: my most carefully structured prompts — the ones with 6-phase methodologies, time budgets per phase, numbered step-by-step instructions — performed worse than simpler, goal-oriented versions. The model's internal reasoning was better than my prescribed steps. I wasn't helping it think; I was constraining it from thinking well.
Anthropic's documentation on Opus notes that the model is "more responsive to system prompts" and "takes instructions literally." What they're politely saying: stop over-engineering your prompts. The model will follow your 6-step methodology to the letter, even when its own reasoning would have found a better path.
That realization changed everything. I stopped writing new prompts and built a prompt-creator skill — a routing layer that classifies the task, selects the right prompting approach based on use case and target model, and pulls quality patterns from the library as references rather than templates. The 46 prompts didn't disappear. They became a pattern library the router consults.
This article covers how a prompt-creator skill works as a router, why reasoning models demand different prompt design, and how to organize prompt patterns by use case. These patterns come from running 46 prompts across 8 workstreams in production for 2.5 years.
If you already use AI for GTM work — if you've saved prompts, built a library, noticed that some produce excellent output and others produce mediocre results for no obvious reason — this explains why.
Why Reasoning Models Broke My Best Prompts
There's a direct, measurable relationship between model capability and optimal prompt structure. The more capable the model, the less prescriptive your instructions should be.
I tested this. My tech stack discovery prompt was built with a 6-step methodology: "Phase 1: Quick Signals (60 seconds). Phase 2: Deep Investigation (90 seconds)..." and so on. Each phase had specific instructions about which sources to check and how to validate findings. On Sonnet, this structure produced consistently strong results. On Opus, the same prompt produced narrower results — the model followed my phases so faithfully that it never explored avenues I hadn't prescribed.
When I replaced the methodology with a goal statement, constraints, and an output format, Opus found signal sources I hadn't thought to include. The knowledge I'd encoded in the 6-step methodology was less complete than the model's own reasoning.
| Model Tier | Optimal Approach | Why |
|---|---|---|
| Frontier (Opus, o1, o3) | Goal-first, minimal instructions | Over-specification constrains superior reasoning |
| Standard (Sonnet, GPT-4o) | Hybrid approach | Benefits from structure without heavy constraint |
| Efficient (Haiku, GPT-3.5) | Instruction-heavy | Needs external structure to guide execution |
Here's what "goal-first" looks like in practice. The tech stack discovery prompt went from:
"Step 1: Deep Scan of Career Pages — Navigate to: {company_domain}/careers, /jobs — Scan ALL job descriptions for engineering roles — Extract every specific tool name from 'Requirements' sections"
To:
"CONSTRAINTS: Primary sources: careers pages ({company_domain}/careers, /jobs), official repos, current employee posts. Extract from: 'Requirements', 'Qualifications', 'Nice to Have' sections. Use exact tool names as found in source."
The knowledge is preserved. The sources, extraction targets, and specificity requirements are all there. What changed is the framing — from "here's how to think" to "here's what I need and where to look." The model fills in the how with reasoning better than my prescribed steps.
Anthropic's prompt engineering guide covers the fundamentals. For extended thinking, they recommend "prefer general instructions first, then add specificity if needed." This article is the practitioner's version — what happens when you internalize those fundamentals across 46 prompts.
The implication for anyone with a prompt library: if you have instruction-heavy prompts built for earlier models, those prompts are now references — sources of domain knowledge, quality standards, and output schemas. They're not execution templates. The gold is in what they know, not how they tell the model to think.
The Prompt-Creator Pattern — A Routing Skill, Not a Template
Once I understood the model-capability relationship, the operational question was: how do I apply this consistently without manually restructuring every prompt for every model on every task?
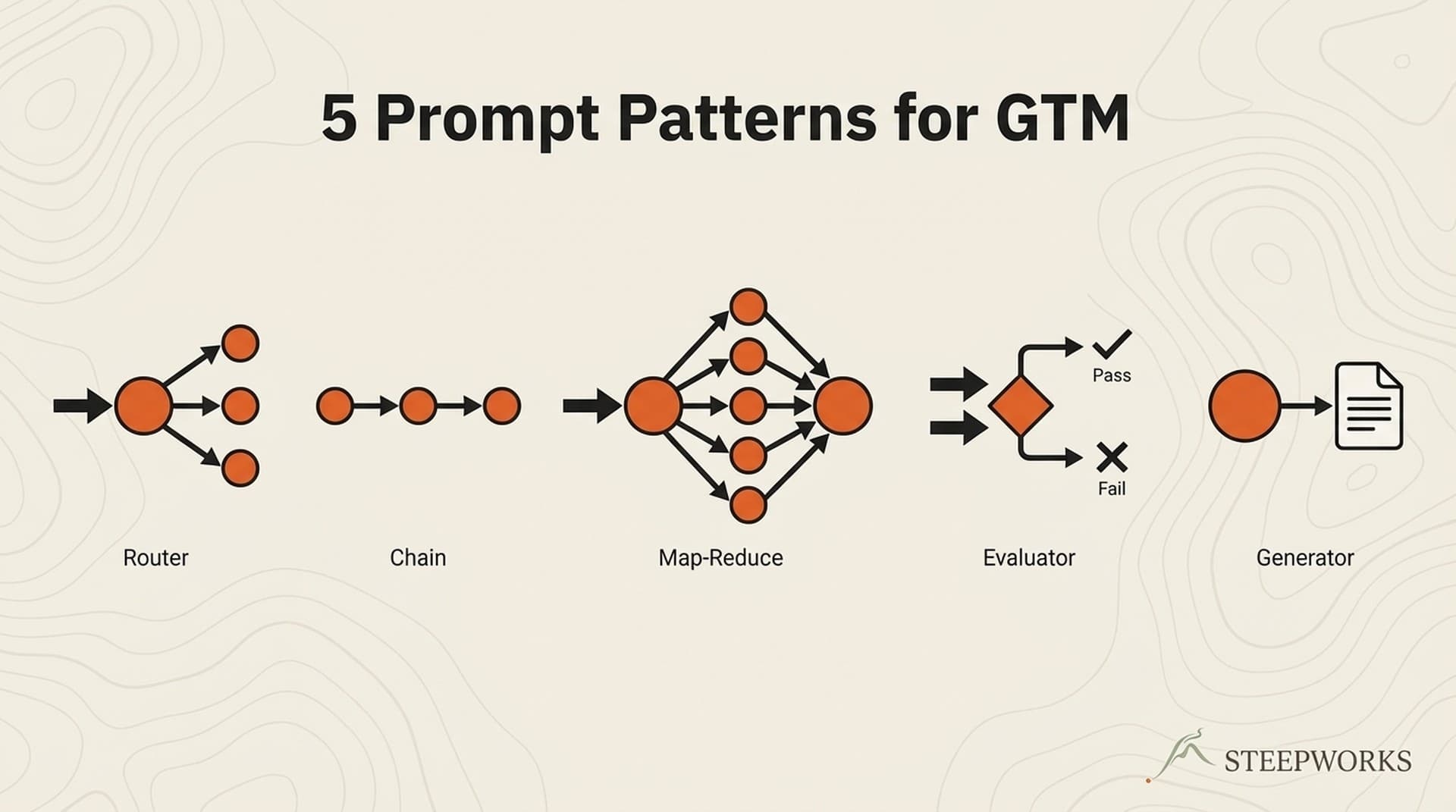
A routing skill. Not a template. Not a library. A classifier that takes a task description and makes three decisions: what archetype does this task match, what model will run it, and what quality standards apply.
The router dispatches between five archetypes covering every GTM prompt I've built in 2.5 years:
| Archetype | Use When | Key Characteristics |
|---|---|---|
| Research/Discovery | Extract info from web/sources | Source priority, stop conditions, evidence requirements |
| Classification/Scoring | Categorize or score inputs | Tier definitions, evidence examples, confidence levels |
| Synthesis/Analysis | Combine sources into insight | Multi-source integration, framework application |
| Extraction/Parsing | Pull structured from unstructured | Input classification, section-based output, null handling |
| Multi-Agent Synthesis | Process 10-100 documents | Parallel extraction, confidence scoring, quality gates |
Three routing questions:
- What specific outcome do you need? (Selects the archetype.)
- What inputs will the prompt receive? (Shapes the input contract.)
- How will you know if the output is good? (Defines quality controls.)
From those answers, the router selects the archetype and — this is what most people miss — selects the instruction pattern based on target model. Opus gets a goal-first prompt. Sonnet gets a hybrid approach. Haiku gets detailed step-by-step. Same task, same quality standards, different structure.
The library doesn't disappear. It becomes a reference layer. Step 0 of every routing workflow is mandatory: search the library first. But the decision matrix changes:
- USE AS-IS — Same task, targeting Sonnet or Haiku. The library prompt works.
- RESTRUCTURE — Same task, targeting Opus. Extract quality patterns into goal-first format.
- ADAPT — Same type of task, different domain. Pull patterns from the closest match.
- CREATE NEW — Novel task. Still mine the library for quality patterns and output schemas.
This is systems-over-tactics thinking applied to prompt engineering. A prompt library is a collection of artifacts. A prompt router is infrastructure that compounds — every new pattern makes the router better at classifying the next task.
For teams, this matters even more. A prompt-creator skill means your newest team member gets the same prompt quality as your most experienced operator. They describe what they need; the router classifies, selects, and constructs.
Prompt Patterns by Use Case — What the Router Dispatches
Research & Intelligence
Use cases: Competitive analysis, tech stack discovery, company deep research, market intelligence. (See also: prompt engineering sprint)
Pattern: For Opus — goal-first with constraints. For Sonnet — phased methodology with time budgets. Both inherit evidence standards from a shared references directory. (See also: claude md)
The key principle: upstream/downstream separation. Research prompts must describe reality, not recommend actions. A single prompt that researches and recommends contaminates the research — the AI unconsciously filters facts to support the strategy it's already forming. (See also: skills)
The gold standard research prompt in my library explicitly blocks inference: "No 'likely,' 'suggests,' 'implies'" in the output. The router enforces this automatically for research archetypes.
Before upstream/downstream separation, I'd get research that conveniently supported whatever strategic direction the model was leaning toward. After the split, the research became uncomfortable sometimes — findings that contradicted my assumptions. That's when I knew it was working.
Prospecting & Qualification
Use cases: Lead enrichment, ICP classification, buyer role scoring, contact verification.
Pattern: Framework + Scoring works across all model tiers for classification because these tasks need explicit tier definitions regardless of model capability. An ICP buyer role classifier defines exact scoring rubrics, seniority tiers, and structured output schemas. Those survive any restructuring — they're domain knowledge, not process instructions.
The key principle: measurable criteria over vibes. "Score as Good/Medium/Poor" produces inconsistent results across runs. "Score 1-5 based on: direct title match (+2), budget authority signals (+1), tech stack overlap (+1), hiring signals (+1)" produces reproducible output. The router enforces structured scoring for every classification task.
Synthesis & Content Production
Use cases: Competitive intelligence synthesis, newsletter generation, article production, customer voice rollups.
Pattern: For Opus — goal-first with quality constraints from the library. For Sonnet — section-based with explicit framework application. Synthesis is where goal-first produces the largest improvement, because the model's ability to integrate multiple sources exceeds any step-by-step recipe I could write.
A concrete example: my competitive intelligence synthesis prompt originally prescribed a 4-section methodology — feature matrix, battlecard generation, win/loss patterns, trap questions. Each section had specific analysis instructions. When I restructured for Opus: "Produce a competitive landscape analysis. Include feature comparison, battlecard-ready positioning, win/loss patterns with evidence, and strategic trap questions for sales conversations. Apply evidence standards from shared references." Same output quality. Half the prompt length. And the model cross-referenced win/loss patterns with feature gaps in ways my methodology never specified.
Customer Intelligence
Use cases: Call transcript analysis, MEDDPICC extraction, voice-of-customer strategy synthesis.
Pattern: Extraction with adaptive logic. The call synthesis prompt classifies the input type first — discovery call, demo, negotiation, QBR — and adapts extraction criteria accordingly. A negotiation call and a discovery call contain different signals; extraction should adapt.
The key principle: input classification before extraction. The router adds this step to every extraction prompt automatically. Extraction prompts that worked on discovery calls produced garbage on negotiation calls because the signal landscape is fundamentally different. The classification step prevents that mistake from repeating.
The Quality Controls That Survive Every Restructuring
Goal-first prompting doesn't mean vague prompting. The most common reaction I get: "So you just... ask it to do the thing?" No. You ask it to do the thing with explicit quality controls.
When restructuring a prompt from instruction-heavy to goal-first, the methodology changes but the quality infrastructure stays. Evidence standards, null protocols, confidence scoring, output schemas, and stop conditions all survive.
| What to KEEP from the library | Where it moves in goal-first |
|---|---|
| Evidence standards (citations, confidence levels) | CONSTRAINTS section |
| Output formats and schemas | OUTPUT FORMAT section (unchanged) |
| Quality controls (null protocols, verification) | CONSTRAINTS section |
| Domain-specific criteria | GOAL or CONSTRAINTS |
| Anti-patterns and edge cases | CONSTRAINTS section |
Every prompt the router produces gets validated against six checks. These come from 2.5 years of production failures:
- Defined output format with schema and example. Without it, the model invents a format — sometimes a different format each run.
- Evidence requirements with citation standards. "Cite your sources" is vague. "Include [SOURCE: URL] for every factual claim, [INFERRED: reasoning] for deductions, [ASSUMPTION] for gaps" is specific.
- Bounded output with max limits. Without bounds, models produce 3,000 words when you needed 500.
- Null handling protocol. What should the model do when it can't find information? "Leave blank" and "write 'Not found'" and "flag for human review" are three different answers that matter in production.
- Specific role definition. Not "You are a helpful assistant." "You are a competitive intelligence analyst producing a battlecard for an AE preparing for a demo against [competitor]."
- Confidence assignment. "High confidence — multiple corroborating sources" vs. "Low confidence — single source, may be outdated" is the difference between acting on intelligence and acting on guesses.
Any missing element means the prompt isn't production-ready. The router won't ship it until all six pass.
I also enforce anti-bias controls on upstream research prompts. Even structurally sound research prompts can contaminate output through tone. If the prompt describes an industry with "razor-thin margins," the model confirms fragility instead of testing it. The router's anti-bias checklist: no superlatives that predetermine conclusions, no emotional language disguised as analysis, section titles that frame open questions instead of assertions, and confidence grading on all inferences.
The quality controls are the real intellectual property in a prompt library. Not the step-by-step instructions (which reasoning models outperform), not the role definitions (which are standardizable), but the hard-won knowledge of what evidence standards to apply, what null protocols to enforce, and what anti-patterns to prevent.
Building Your Own Prompt Router — Starting Monday
This doesn't require a 4,700-file knowledge system. About 5 hours of focused work spread across a week.
Step 1: Audit your existing prompts by use case (1 hour). Take every prompt you've saved — Notion, Google Doc, CLAUDE.md, wherever — and sort them. Research? Classification? Synthesis? Extraction? Most operators I've talked to have 80% in 2-3 categories. Those are your starting archetypes.
Step 2: Extract the quality patterns (2 hours). From each prompt, pull the reusable elements: evidence standards, output schemas, null protocols, scoring rubrics, domain-specific criteria. Put them in a shared references directory — separate from the prompts themselves. These references get imported by any new prompt, regardless of archetype.
As Martin Fowler describes it, this is context engineering — "the deliberate practice of filling an LLM's context window with the information most likely to help it solve a task correctly."
Step 3: Build one routing decision (30 minutes). Start simple. Three if-statements: "If classification task, use Framework + Scoring. If research, use Goal-First with evidence constraints. If extraction, use Section-Based with input classification." The value isn't in the sophistication — it's in the existence of the router. Any classification system beats none.
Step 4: Add model awareness (15 minutes). One more decision layer: "If frontier model, goal-first. If standard model, hybrid. If efficient model, detailed step-by-step." This single decision improved my prompt output quality more than any other change in 2.5 years.
Step 5: Test by restructuring one prompt (1 hour). Take your best-performing research prompt. Extract its quality patterns into shared references. Rewrite as goal + constraints + output format. Run both versions on the same input. Compare. In my experience, the goal-first version matches or exceeds the original on frontier models.
For teams, the highest-return move is Step 2 — extracting quality patterns into shared references. One person maintains the evidence standards, the scoring rubrics, the null protocols. Every prompt inherits them. That's how a team of five gets the prompt quality of the most experienced operator.
The maturity path: scattered prompts, organized library, routing skill, automated quality gates. You don't need to jump to the end. But knowing the destination helps. Every prompt you write today becomes a reference pattern for the router tomorrow.
A knowledge operating system built on these patterns is where this approach leads at scale. But you start with Step 1 on Monday morning.
The Shift
A prompt library is a collection of solved problems. A prompt router solves new problems using patterns from solved ones.
The patterns here — model-aware structure selection, archetype classification, upstream/downstream separation, quality controls as constraints, shared references as context engineering — aren't theoretical. They came from restructuring 46 prompts across 8 workstreams and noticing what survived: not the step-by-step instructions, but the quality standards, the evidence requirements, the domain knowledge.
The step-by-step instructions were scaffolding. The quality controls are the building. Reasoning models made the scaffolding optional.
Build the router.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.