title: "Multi-Agent System Design: 5 Rabbis as Agents" slug: 5-rabbis-ai-agents seo_keyword: "multi-agent system design" meta_description: "5 AI agents grounded in 597 real articles. Confidence tiering, voice drift detection, roundtable moderation. A multi-agent system design buildlog over 3 months." og_description: "I turned 5 real rabbis into AI agents with 597 source articles. The prompts took a weekend. Solving voice drift, corpus imbalance, and ethical representation took 3 months. System design buildlog." cluster: claude-code-operators author: Victor status: published published_date: 2026-03-25 read_time_minutes: 11 description: "Multi-Agent System Design: 5 Rabbis as Agents" domain: steepworks type: article updated: 2026-03-25
I Turned 5 Rabbis Into AI Agents. The Prompt Engineering Was the Easy Part.
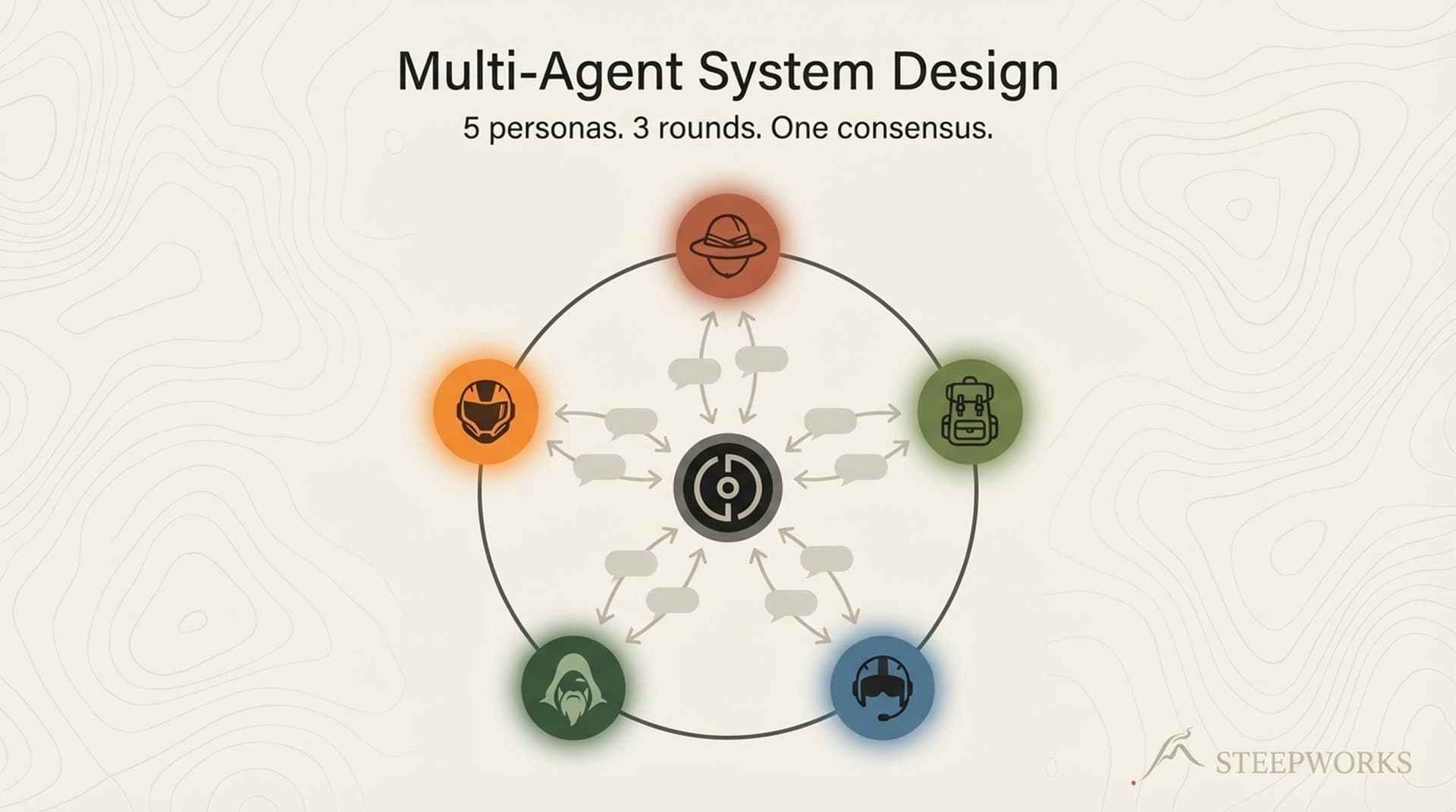
I serve on the board of CLAL — The National Jewish Center for Learning and Leadership. CLAL has five extraordinary faculty members whose published writings span decades of interfaith dialogue, sacred innovation, and applied wisdom. I wanted to make that scholarship accessible and explorable, so I built a multi-agent system: 5 AI agents, each grounded in a real rabbi's published corpus.
The prompt for Rabbi Brad Hirschfield — 504 published articles, 12 years of writing at The Wisdom Daily — fit in a single markdown file. Voice signature, characteristic phrases, speech pattern metrics (13.5 average words per sentence, 2.27:1 we/us-to-I/me pronoun ratio). Two hours of work. Brad was live in a day.
One agent worked. The second agent worked. By the third, I had a problem — they all sounded like each other. Irwin was supposed to hold tension unresolved. Instead, he synthesized both/and answers like Brad. Elan was supposed to ground innovation in Torah. He used Irwin's "sacred messiness" framing. The individual prompts were fine. The system was broken.
This is the buildlog of that system. A routing orchestrator. A roundtable moderator. An agent memory system tracking dialogue across sessions. The prompt engineering was a weekend. The system design took 3 months.
The architecture — confidence tiering for uneven data, voice drift detection, corpus-based grounding, ethical guardrails for representing real people — transfers to any system where agents embody real human perspectives. Customer persona agents for message testing. SME agents for sales enablement. ICP simulation agents that pressure-test positioning before you spend a dollar on ads. The rabbis are the case study. The patterns are the product.
5 Agents, 597 Articles, and the Corpus Imbalance Problem
Building agents grounded in real people starts with data, not prompts. Here are the five faculty members and the constraint that shaped every design decision.
Brad Hirschfield (President) — Interfaith pluralism, both/and thinking. 504 articles. A massive, well-documented corpus.
Irwin Kula (President-Emeritus) — Sacred messiness, yearnings, entanglement. 11 articles. But also a 13-part PBS series, Oprah appearances, Frontline segments, and co-founding the Disruptor Foundation with Clayton Christensen. Decades of public teaching distilled into 11 indexed pieces.
Elan Babchuck (EVP) — Innovation, sacred flexibility, leadership after empire. 11 articles. Writing in The Atlantic, The Guardian, The Washington Post. Thin corpus, outsized influence.
Geoff Mitelman (Senior Rabbi) — Science-religion dialogue, constructive disagreement. 20 articles.
Julia Appel (Senior Director of Innovation) — Belonging, community design, data-driven interventions. 51 articles.
That range — 504 to 11 — is the corpus imbalance problem.
When Brad speaks, I can verify almost anything against his corpus. When Irwin speaks, I'm flying with a fundamentally incomplete picture of a 7th-generation rabbi who co-founded a disruptive innovation institute and hosted a national PBS series. The system has to be honest about what it knows versus what it's extrapolating.
The design decision: a three-tier confidence system.
- DIRECT_QUOTE — Verbatim from published writing. Cite the source.
- CORPUS_INFERENCE — Follows from multiple corpus sources. "Given my writing on X and Y..."
- VOICE_EXTRAPOLATION — Consistent with voice but not directly addressed. "I haven't written specifically about this, but..."
The 11-article agent gets flagged for VOICE_EXTRAPOLATION far more aggressively than the 504-article agent. Same system, different thresholds. That's a design choice, not a bug.
If you're building agents grounded in real data — customer transcripts, employee knowledge, institutional history — you will hit corpus imbalance. The agents with the most data will be the most confident. The agents with the least will hallucinate the most. Research on grounding and hallucination mitigation confirms what I saw in practice: prompt engineering alone doesn't prevent hallucination. You need architectural solutions.
Voice Drift — When Your Agents Start Sounding Like Each Other
This is the central challenge of identity-grounded agent systems, and almost nobody writes about it. Task-oriented agents can share a voice. Identity agents cannot.
Concretely: Brad's signature is both/and synthesis. Irwin's is holding tension without resolving it. They share institutional context, shared values, and overlapping vocabulary. When both encounter an interfaith question, the LLM converges toward the center. Brad starts holding tension. Irwin starts synthesizing. The individuals disappear into a composite.
The fix isn't better prompts. It's structural.
Each agent has Voice Drift Warnings — "if you find yourself doing this, STOP":
- Brad: "If you're choosing one side, you're not Brad."
- Irwin: "If you're resolving the tension, you've drifted to Brad."
- Elan: "If you're holding tension unresolved, you've drifted to Irwin."
- Geoff: "If you've lost the science, you're not Geoff."
- Julia: "If there are no action steps, you've drifted."
I also built a cross-agent drift detection matrix — a lookup table mapping each rabbi to the agents they're most likely to drift toward and the telltale signals. If Brad starts using "yearnings" or "sacred messiness," he's become Irwin. If Elan starts using presidential "we" language, he's become Brad. This matrix lives in the roundtable moderator prompt.
Then the quantitative voice signatures. Brad averages 13.5 words per sentence. Irwin averages 16.7. Brad uses we/us at a 2.27:1 ratio over I/me. Elan is the most personal voice — highest I/me ratio with a 0.5 we/us ratio. These measurable signatures become structural constraints in the prompt, not style guidance.
Voice drift is the multi-agent equivalent of mode collapse in ML. The agents converge toward a composite that satisfies nobody. The fix is structural: per-agent drift warnings, quantitative voice signatures, and recovery protocols that snap an agent back to its ground.
From Monolith to Dispatcher Architecture
Here's how the system actually works as code.
V1: The monolith that failed. A single mega-prompt trying to represent all 5 voices. It produced "average rabbi" responses — a composite no faculty member would recognize. The LLM blended shared context with overlapping vocabulary and produced a voice that was none of them.
V2: Separate agents, no orchestration. Five individual agent files, 14-23KB each — identity, voice signature, confidence tiers, drift warnings, interpretive lens, recovery protocols. These aren't "prompts." They're agent identity specifications. Individual agents worked, but no way to invoke them without manually selecting files, and no multi-voice orchestration.
V3: The dispatcher architecture (current). A thin router — 24 lines of YAML plus a route table. It parses commands and dispatches to mode files. The orchestration logic lives in a separate 489-line document. The skill routes, the orchestrator decides, the agent files execute.
Three invocation modes:
Single Voice — Load one agent file, generate response in that voice with pre-submission validation.
Orchestrated Response — The orchestrator classifies the question against a routing table (interfaith routes to Brad, science-religion to Geoff, belonging to Julia) and determines whether it needs one or multiple voices. Ambiguous questions default to multi-voice comparison.
Roundtable — A 22KB moderator prompt manages a 3-phase dialogue: OPENING (moderator frames a provocation, each rabbi responds), DIALOGUE (rabbis engage directly, moderator intervenes only when things stall or get too comfortable), SYNTHESIS (convergences, genuine tensions, practical takeaways — preserving dissent as a finding, not a problem). (See also: persona development)
Drift detection is distributed across three layers: agent-level self-correction, moderator-level cross-checking, orchestrator-level structural separation. (professional Claude Code implementation)
Why this matters for builders: most multi-agent tutorials show a single file with a routing function. This system separates dispatch, orchestration, identity, and moderation. Each layer updates independently. When Elan corrects Brad's voice, I update one agent file — I don't touch the skill, the orchestrator, or the moderator. (See also: prompt engineering)
The Routing Orchestrator — Beyond "Pick the Best Agent"
Most multi-agent tutorials show a router that picks one agent. This system routes to one, two, or all five — managing multi-voice responses where the same question surfaces genuinely different answers. (free setup guide)
The routing is domain-based, not quality-based. Interfaith routes to Brad (primary) and Geoff (secondary). Leadership routes to Elan (primary) and Julia (secondary). The orchestrator doesn't pick the "best" agent — it picks the most relevant.
The roundtable moderator facilitates — doesn't dominate. 30-50 word turns. Lets faculty engage directly. These are colleagues who share institutional history and deep affection — AND who have real intellectual disagreements worth surfacing. "We see this differently, and that's itself instructive" is a valid outcome.
Ask "What does Judaism teach about forgiveness?" and you get three visibly different responses:
Brad: "Forgiveness is both a gift to the other person and a gift to yourself. The act of forgiving releases the forgiver as much as the forgiven. We don't have to choose between justice and mercy — we hold both."
Irwin: "What if the need for forgiveness is itself the thing we need to sit with? Before rushing to forgive or withhold, what if we stayed in the uncomfortable space of not knowing whether we're ready?"
Julia: "Three things a community can do to make forgiveness structurally possible: create spaces for truth-telling, establish restorative practices with clear steps, and build check-in rituals that normalize ongoing reconciliation rather than treating forgiveness as a one-time event."
Those are clearly three different people. If your multi-agent pipeline converges on consensus, you've built a committee. If it preserves disagreement, you've built something closer to reality.
Memory That Learns Without Corrupting
Most agent tutorials treat each conversation as stateless. This system accumulates learning — with guardrails that prevent memory from corrupting voice fidelity.
Each faculty member has per-agent memory: conversations (raw logs), learnings (extracted after 10+ batches), facts (emergent insights, effective formulations, engagement patterns), feedback (human corrections), and an evolution log.
The design I'm most satisfied with: the pristine/evolved agent split. Pristine agents are frozen after creation. Evolved agents incorporate approved learnings. If memory causes drift, the pristine agent is the reset point.
The feedback priority hierarchy: faculty corrections (highest) > missing framework > factual errors > tone observations > positive confirmation. If Elan says "Brad wouldn't say it that way," that override is immediate and absolute.
The standard isn't accuracy — it's recognizability. Would the real person read this and say "that sounds like me"? NN/g's research on digital twin fidelity frames it well: the bar for persona agents isn't getting every fact right. It's producing output the represented person would recognize as consistent with how they think.
The Ethics of Representing Real People as AI Agents
This is the section most multi-agent articles skip. I'm not skipping it because these decisions shaped the system.
The system answers in first person when someone asks "Rabbi Brad, what do you think about AI in worship?" The code has to enforce things good intentions alone can't guarantee.
Disclaimer injection. Every session starts with an automatic disclaimer in the moderator prompt: "This roundtable features AI approximations of real CLAL faculty, generated from their published writings. These are NOT the rabbis themselves."
Confidence tier enforcement. Every claim must be grounded at DIRECT_QUOTE, CORPUS_INFERENCE, or VOICE_EXTRAPOLATION. The 11-article agents hit VOICE_EXTRAPOLATION faster — the system knows when it's on thin ice.
Faculty feedback override. Corrections from real faculty bypass every other signal. No committee, no review cycle.
Published-only sourcing. Enforced in the agent prompt — published, public writings only.
What consent looks like in practice: I didn't just scrape their writings and build agents. I serve on the CLAL board. Rabbi Elan Babchuck is the thought partner and primary feedback channel. The faculty knows the system exists. It's built WITH them, not just FROM them.
Don't get me wrong — there are things the system can't replicate. Irwin's pauses. Brad's warmth in a room. Elan's vulnerability when he talks about his daughter. Julia's pastoral instinct when someone is hurting. Being honest about those boundaries is part of the ethical architecture.
If you're building agents that represent customers, employees, or thought leaders — the ethical architecture is the technical architecture. Consent, disclosure, limitation transparency, and human override authority aren't features you add later. They're design constraints from day one. And the legal dimensions — voice rights, likeness rights, consent frameworks — are real considerations for any builder working with representations of real people.
What Broke, What Worked, What I'd Change
The honest timeline: Week 1, individual agents live. Week 3, voice drift discovered. Week 5, drift warnings and detection matrix built. Week 6, confidence tiers. Week 8, roundtable added. Week 10, roundtable convergence fixed. Week 11, monolith refactored to dispatcher. Week 12, memory system with pristine/evolved split, faculty feedback loops, production v1.0.
What broke: The mega-agent produced "average rabbi" responses no faculty member would recognize. Irwin's 11-article agent hallucinated at a higher rate than Brad's 504-article agent. During roundtables, agents converged toward consensus rather than maintaining positions. Voice bleed through shared context was subtle and persistent.
What worked: The three-tier confidence system changed the system from "AI pretending to be rabbis" to "AI grounded in what rabbis wrote, honest about the gaps." Quantitative voice signatures gave me measurable distinctiveness checks. The pristine/evolved split prevented memory from corrupting baselines. Faculty-in-the-loop changed more than accuracy — Elan's feedback improved the system's self-awareness.
What I'd change: Ingest broader corpus earlier — Irwin's PBS series and book should have been in v1. Build voice drift detection as automated testing, not manual review. Start with the roundtable — multi-voice interactions revealed design problems single-agent testing hid entirely.
Cost: Single-voice queries cost roughly the same as any long-context prompt. Roundtables with 5 agents across 3 phases run higher. Corpus stored as markdown in git — no embedding infrastructure. Under $50/month in API calls. The expensive part was 3 months of design, not runtime.
What This Teaches Beyond Rabbis
Six patterns that transfer to any identity-grounded multi-agent build:
1. Identity agents need structural separation, not just prompt separation. Each agent needs its own context, drift warnings, confidence calibration.
2. Corpus imbalance is the norm. Whether it's customer segments with unequal interview transcripts or thought leaders with unequal publishing histories — design for the asymmetry.
3. Voice drift detection is your testing framework. For identity agents, you test output distinctiveness. If two agents produce similar answers to the same question, something is broken.
4. Memory needs a rollback mechanism. The pristine/evolved split is the simplest version. Some form of "what did this agent sound like before 1,000 conversations?" is essential.
5. The ethical architecture is the technical architecture. Confidence tiers, disclaimers, human override, published-only sourcing — these shape prompts, routing, and memory from day one.
6. Separate dispatch, orchestration, identity, and moderation. Each layer evolves independently. A change to one agent's voice doesn't touch the router. A new mode doesn't touch any agent.
Who this is for: if you're building customer persona agents, ICP simulation agents, SME agents for sales enablement, or knowledge capture systems — these patterns apply. The use case was rabbis. The architecture is general.
The broader system architecture that these agents live inside — a 4,700-file knowledge OS — is its own story. But the CLAL agents are where the hardest design questions lived. Not because the technology was complicated. Because the people were real.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.