title: "AI Knowledge Management Across 8 Workstreams" slug: bidirectional-memory-sync seo_keyword: "AI knowledge management" meta_description: "AI knowledge management across 8 workstreams: a consulting insight sat unused for 3 weeks. Bidirectional memory sync across 889 docs fixed it." og_description: "AI knowledge silos aren't a communication problem -- they're an architecture problem. 889 documents, 556 knowledge graph edges, 3 agents sharing context across 8 workstreams. Built from flat files, no database." cluster: knowledge-systems author: Victor status: published published_date: 2026-03-25 read_time_minutes: 9 description: "AI Knowledge Management Across 8 Workstreams" domain: steepworks type: article updated: 2026-03-25
Bidirectional Memory Sync: AI Agents Share Context Across 8 Workstreams
A consulting insight about sales qualification sat in a folder for three weeks. The agent working on product design had no idea the consulting agent had discovered it. Same repository. Same AI tools. Zero shared awareness.
You can remind a colleague: "Hey, did you see what we learned in that customer call?" You cannot remind an AI agent. Every new conversation is a hard reset. The context evaporates -- not because the knowledge is lost, but because no one told the agent where to find it.
Human knowledge silos are a communication problem. AI knowledge silos are an architecture problem.
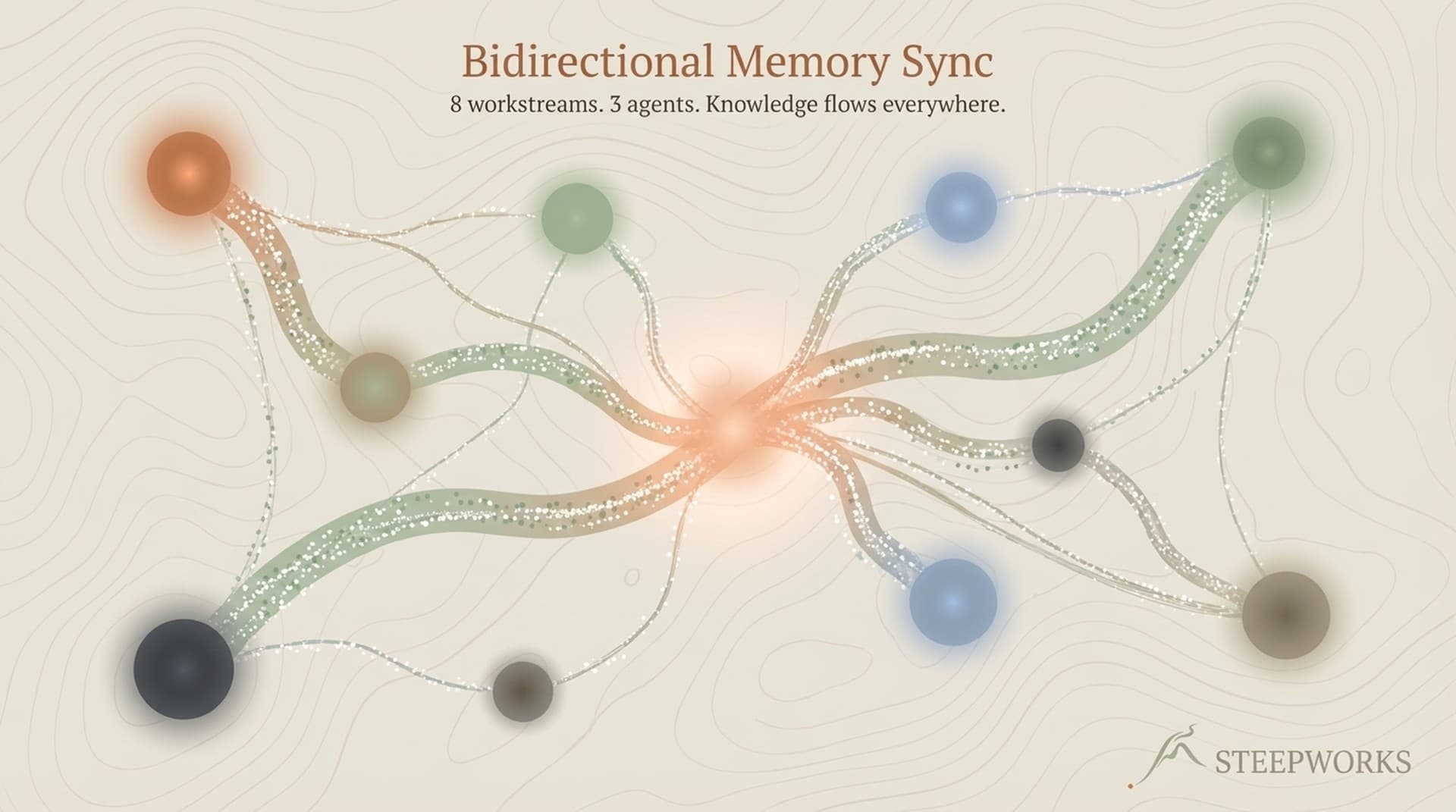
Over 18 months, I built a system where 3 AI agents share context bidirectionally across 8 workstreams. 889 documents, 556 knowledge graph edges, and a session recovery protocol that means no conversation starts from zero. Not a SaaS tool -- a file-based architecture grown incrementally from a single folder. Bidirectional memory sync isn't a feature you install. It's an architecture you grow.
Most advice on this topic focuses on search and retrieval. What actually matters: making sure an insight discovered in one context shows up where it's needed in another -- automatically, without someone remembering to copy-paste it.
The Problem Worth Solving
Enterprise approaches to this optimize search -- finding what you already know exists. The harder problem is context propagation: knowledge discovered in one domain surfacing where it's relevant in another.
The silo problem isn't reserved for large companies. Eight different work contexts -- consulting, content, product, newsletter operations, finance, infrastructure, personal projects -- each producing insights the others need. Every new AI conversation starts from zero.
Bloomfire reports that 68% of organizations cite knowledge silos as a top concern. But that statistic captures organizational silos. What I'm describing is smaller: silos between your own AI sessions, within your own work.
The cost: 10 AI sessions per day, 5 minutes of context re-establishment per session -- 50 minutes daily spent re-explaining decisions already made. Scale to a marketing team of 12 and you're burning 10 hours collectively per day. Across a month, 200+ hours of team capacity lost.
Before building this architecture, I hit three failure modes:
Context evaporation. Five minutes per conversation re-explaining which workstream I was in, what had shipped, what decisions were pending. The files were right there. No one told the agent to look.
Workstream isolation. The consulting agent never saw what the newsletter agent had discovered about audience segmentation. The product agent didn't know what the content agent had learned about positioning. Insights stayed trapped in the domain that produced them.
One-directional flow. Instructions flowed down -- human to agent. Discoveries never flowed back. The agent would learn something valuable, generate useful output, and forget all of it next session.
Why doesn't search solve this? You can only search for what you know to look for. A side project developed a 4-tier agent memory pattern. That pattern sat unused for weeks until I manually noticed it could solve the workstream context problem across my entire system. Without architecture designed for cross-domain flow, that connection would still be buried.
The academic research on implementation confirms what I discovered empirically: the hardest problems aren't technical. They're architectural.
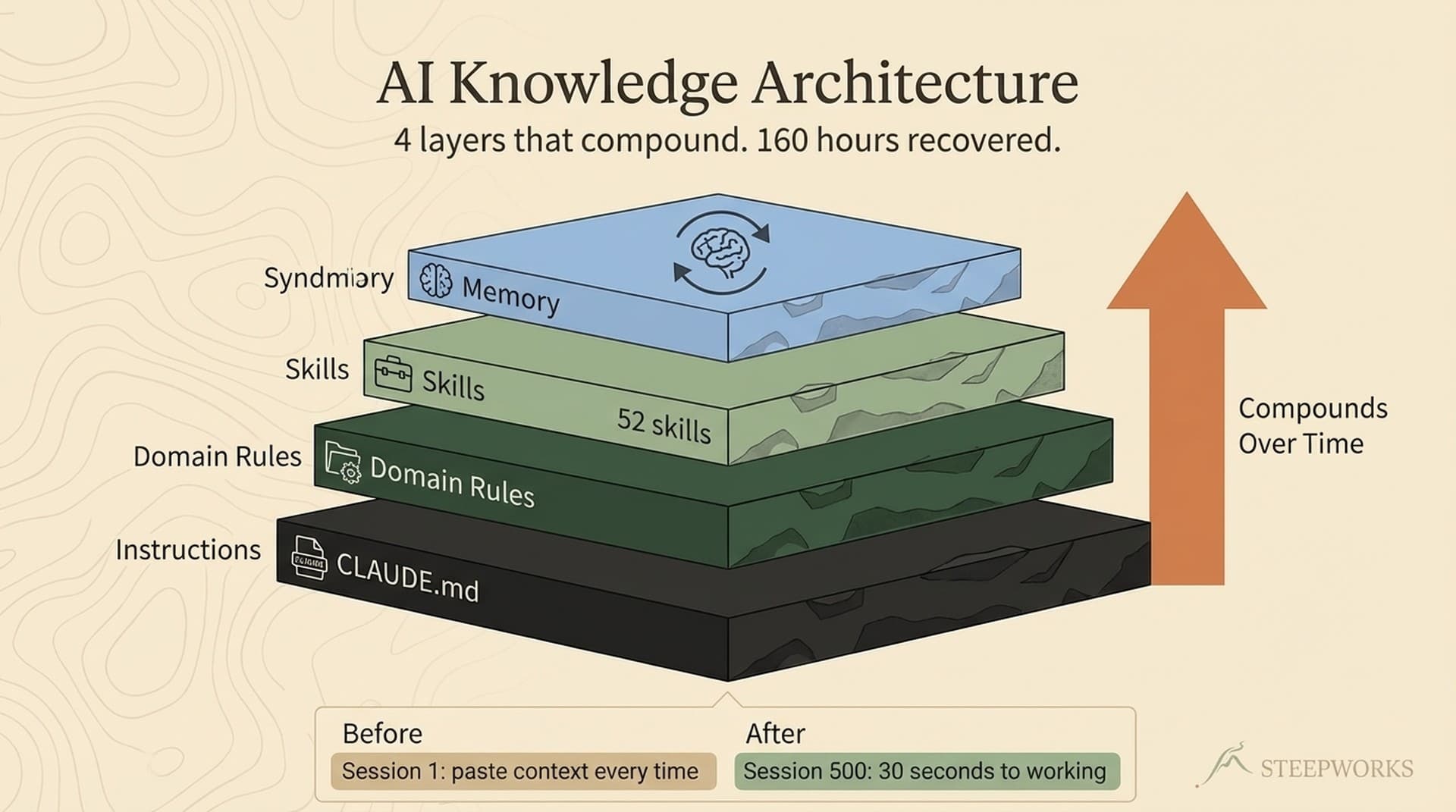
The Memory File System: Architecture for Context That Compounds
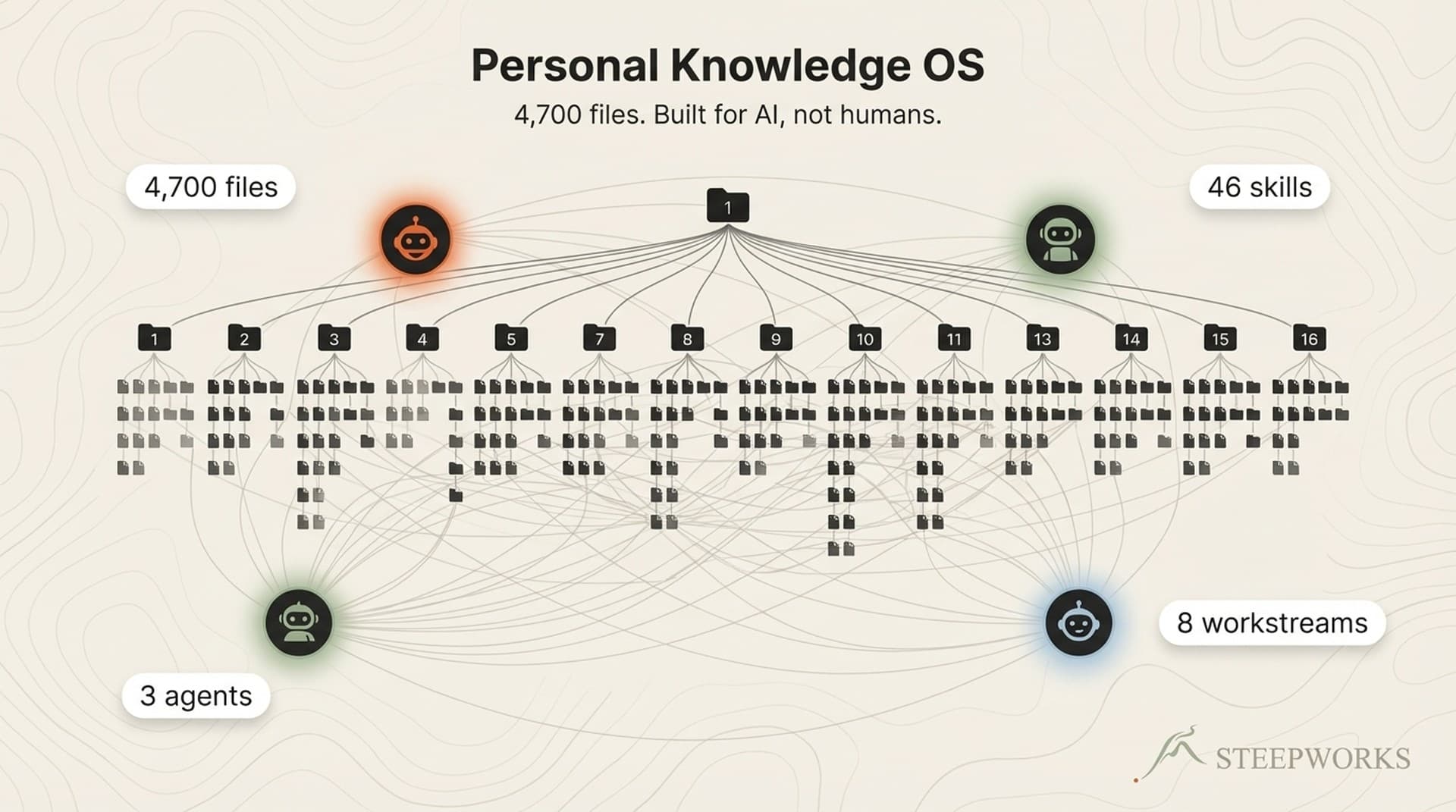
I'll describe this at 889 documents because that's what I run. But I started with fewer than 100, and the core pattern hasn't changed. Everything scales down.
The foundation: 17 numbered domain folders, 889 documents, 756 with structured YAML frontmatter (85% coverage). Every document carries metadata -- domain:, tags:, status:, type: -- feeding an auto-generated knowledge graph. 556 links between documents, all derived from frontmatter. Not hand-curated. The graph costs zero ongoing effort. The investment is in frontmatter discipline, not graph curation.
Why files over a database? Three reasons. AI agents read markdown natively -- no API layer, no query language, no abstraction. Git provides full version history with zero infrastructure. And the system is portable -- no vendor lock-in, no database maintenance. Any agent that can read files can participate.
The memory system operates across three tiers:
Tier 1: MEMORY.md -- persistent memory surviving conversation boundaries. 21 active memories, periodically trimmed from 214 lines to ~90. Organized by category: architecture decisions, patterns, gotchas, context. Ten deep-dive topic files loaded on demand. The agent doesn't carry everything -- it knows where to look.
Tier 2: Workstream briefs -- organism-layer summaries. Eight briefs, ~300 words each, covering every active work context. The connective tissue.
Tier 3: Knowledge graph -- structural relationships between all documents. Auto-generated from frontmatter, refreshed by weekly health checks. Surfaces connections no single document contains.
One rule holds it together: the anti-sprawl discipline. Default behavior is editing existing files, not creating new ones. Without this, AI agents create files faster than humans can organize them. Every agent follows this rule. It's the single most important architectural decision I made.
What breaks without health checks? My first deep validation found 73.9% broken wikilinks -- 610 out of 825. Silent decay. The kind that makes things slowly stop working without anyone noticing. Automated weekly checks caught it. Manual review never would have.
If you're building something similar: start with the migration and frontmatter discipline.
Workstream Briefs: The Connective Tissue
These are the single highest-leverage component you can implement today. About 30 minutes to set up.
A workstream brief is ~300 words giving any AI agent situational awareness. Five sections:
- Current State -- 2-3 sentences on what's happening now
- Recent Activity -- 3-5 bullets from the last 30 days
- Key Decisions and Open Questions -- what's decided, what's unresolved
- Cross-Workstream Connections -- how this relates to other domains
- Evolution Notes -- how the workstream has changed
I run eight: consulting, content product, knowledge system, newsletter operations, spirituality project, personal blog, finance, infrastructure. An agent reads all 8 in under 4,000 tokens -- about 4% of a standard context window.
The bidirectional sync:
Down: At session start, the agent loads the brief. Immediate context. No re-explanation.
Up: After significant work, the agent updates the brief. A consulting engagement closes, the brief gets refreshed.
Sideways: The Cross-Workstream Connections section maps how domains relate. The consulting brief names the connection: "Every engagement is a Knowledge OS deployment. Learnings feed back into the template."
Maintenance concern? Agents update briefs as part of the workflow, not as a chore. I review all 8 during a weekly audit -- about 15 minutes. The brief isn't a wiki. It's a 300-word snapshot refreshed organically through work.
In your world: if you run content marketing, demand gen, product marketing, and partner marketing as separate AI-assisted workflows, one brief per function means your content agent knows what demand gen learned about conversion messaging -- without you copy-pasting it. (Knowledge OS guide)
Cross-Workstream Insights: When One Domain Teaches Another
The highest-value knowledge isn't within a workstream. It's patterns that emerge between them. (See also: compound knowledge)
Workstream activity tracking. A JSON file tracks file touches per workstream over 7-day and 30-day windows. Hot workstreams get attention -- content at 133 touches in 30 days, knowledge system at 373. Cooling workstreams get flagged. Dormant ones trigger review: done, or abandoned?
The insights system. An append-only log captures cross-cutting patterns from weekly audits. Each insight gets severity, evidence, and resolution status.
Learning rules. Insights requiring behavioral change become persistent rules. A weekly audit detects "the task board has 0 in-progress items despite 29 active projects." That becomes an insight. The insight becomes a rule. The rule shapes how every agent creates and tracks tasks. One observation, permanent behavioral change.
Real cross-workstream flows I've observed: (Claude for operators)
A consulting engagement produces ICP research. That feeds product positioning. Positioning informs content strategy. One insight traverses three workstreams because briefs and the knowledge graph make connections visible.
A newsletter pipeline migration develops infrastructure patterns. Those patterns get adopted by other workstreams building similar data flows.
A multi-agent architecture designed for one project becomes the template for a 7-agent newsletter system in a different workstream. Documented in the first project's brief. Read by the second project's agent at session start.
Microsoft's documentation on AI agent orchestration describes several coordination approaches. What I've built is closest to the blackboard pattern: a shared knowledge substrate that multiple agents read from and write to, with the file system as the board.
The Cross-Workstream Task Board
AI agents need read-write access to your task state, not just documents. Without visibility into what's in flight across workstreams, they can't prioritize or connect work that spans domains.
My implementation: 89 tasks, 7-column flow from triage through done, all 8 workstreams tagged. Dual-write pattern: every mutation writes to an append-only event log (git-auditable) and a materialized current-state file (fast reads). The log is the source of truth.
What broke: dual-write creates duplicates during concurrent sessions. Six duplicate task IDs in one audit. The fix was a dedup guard before materializing state. The architecture doesn't eliminate edge cases -- it surfaces them through automated health checks.
A session start hook reads task state automatically. Every conversation opens with work-in-progress awareness across all workstreams before anyone asks.
Session Recovery: How Context Survives the Reset
The most dangerous moment is the session boundary. Every new conversation is a potential context wipe.
The recovery protocol runs automatically and loads in under 5,000 tokens (~5% of a context window):
- Check for active plan files from a previous session
- Load the relevant workstream brief
- Read learning rules
- Read workstream activity -- hot, cooling, dormant
- Surface work-in-progress from the task board
Before this protocol: ~5 minutes per session re-establishing context. At 8-10 sessions daily, 40-50 minutes. Over a month, roughly 15 hours of re-orientation -- eliminated. For a team of 5 running 6-8 sessions daily, 50-75 hours per month recovered.
The compounding: each session starts smarter because insights from previous sessions are baked into memory, briefs, and rules. Session 50 starts with richer context than session 1 -- not because someone wrote better instructions, but because the architecture absorbed sessions 1 through 49.
You don't need the full architecture for 80% of the value. A MEMORY.md and one workstream brief, loaded at session start, eliminates the worst context evaporation.
Redis's documentation on agent memory architecture outlines the memory types -- episodic, semantic, procedural -- that make stateful systems possible. What I've built implements all three: episodic in session recovery, semantic in the knowledge graph and briefs, procedural in the learning rules.
Stop treating AI sessions as disposable interactions. Start treating them as chapters in a continuous knowledge system.
Your Week 1 Implementation
You don't need 889 documents. Start with: "What did my AI learn yesterday that it should remember tomorrow?"
Day 1: Write one workstream brief. Pick your highest-volume AI work context. Five sections, ~30 minutes:
- Current State -- 2-3 sentences
- Recent Activity -- 3-5 bullets, last 30 days
- Key Decisions -- what the agent should know
- Open Questions -- where judgment is still needed
- Cross-Workstream Connections -- how this relates to other work
Target 300 words. Briefing document, not wiki page.
Day 2: Tell your AI to read it at session start. Add it to your system prompt or project config. Test: does the AI open with context about your workstream?
End of week: Review and update. Add a second brief for your next most active workstream.
Scaling path:
At 2-3 workstreams: Briefs are enough. Cross-domain awareness is immediate.
At 50-200 files: Add MEMORY.md for persistent memory. 21 memories in ~90 lines covers remarkable operational context.
At 200+ files with multiple agents: Implement dual-write for shared state. Consider auto-generated knowledge graphs from structured metadata.
These principles -- bidirectional flow, organism-layer summaries, cross-domain connection mapping -- transfer to any system where AI agents work across multiple contexts. Flat files, git, native file reading. No infrastructure cost. The knowledge graph is auto-generated from metadata you're already writing if you use structured frontmatter.
Total weekly maintenance for 8 briefs, memory trimming, and health checks: under 30 minutes. ZBrain's work on knowledge graphs for agentic AI describes the infrastructure-heavy approach. I've found 80% of the value with 20% of the infrastructure -- starting with the right primitives.
After 18 months building this, the system teaches me things I didn't know I knew. Patterns from one workstream surface as solutions in another. That's not search. That's intelligence.
That consulting insight that sat unused for three weeks? In the current architecture, the workstream brief surfaces it at session start. The cross-workstream connection names it. The task board tracks the embedding work.
The agents don't just share context. They share understanding. And every session, the understanding deepens.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.