title: "AI Text Analysis: 23,442 Utterances, 6 Formats" slug: 23442-utterances-corpus seo_keyword: "AI text analysis" meta_description: "AI text analysis at corpus scale: 23,442 utterances across 6 formats, 3 confidence tiers. Normalizing heterogeneous text into searchable knowledge." og_description: "I built a corpus engine that processes 23,442 utterances from 6 heterogeneous sources into a searchable, confidence-tiered knowledge base. One base class, six extractors. The pattern transfers to any enterprise knowledge problem." cluster: knowledge-systems author: Victor status: published published_date: 2026-03-25 read_time_minutes: 12 description: "AI Text Analysis: 23,442 Utterances, 6 Formats" domain: steepworks type: article updated: 2026-03-25
From 23,442 Utterances to Searchable Wisdom: Building a Corpus Engine
23,442 Utterances, 6 Traditions, and No Common Format
I serve on the board of CLAL — The National Jewish Center for Learning and Leadership — and I'd already built AI agents grounded in the published writings of 5 CLAL faculty rabbis. That project taught me how to model identity, detect voice drift, and enforce confidence tiers on a single tradition's corpus. It also left me with a question: what would it look like to apply the same rigor across traditions? Not comparative religion as a theological exercise, but as an engineering problem — could I build a corpus engine that held Muhammad, Jesus, Buddha, Confucius, Laozi, and Zoroaster in the same schema, with the same confidence standards, searchable by the same downstream agents?
That's what this buildlog is about. Not the theology. The pipeline.
Every AI text analysis guide I read started with "first, load your corpus." As if the corpus already existed in some tidy format waiting to be ingested.
Mine didn't.
I had 23,442 utterances from 6 spiritual leaders. Muhammad's teachings arrived as structured JSON from a hadith API -- 21,678 records with grading metadata baked in. Jesus's speech came as tab-separated Greek New Testament data with morphological codes. Buddha's suttas were bilingual JSON from SuttaCentral. Confucius and Laozi were plain-text Project Gutenberg downloads -- Legge's 1893 and other classical translations. Zoroaster's Gathas were HTML scraped from a 1990s academic site that looked like it hadn't been touched since Bill Clinton's second term.
Six leaders. Six formats. Six completely different scholarly traditions for determining what's authentic.
The hard part of AI text analysis isn't choosing an NLP library or spinning up a vector database. It's data modeling -- staring at six heterogeneous source formats and designing a schema that holds all of them without losing what makes each one distinct. That's the work nobody writes about because it's unglamorous, domain-specific, and full of judgment calls no framework can automate.
This is a buildlog of the corpus engine I built -- a pipeline that ingests heterogeneous source material, applies scholarly confidence tiering, normalizes everything into a searchable schema, and feeds downstream AI agents.
Every organization has its own version of this problem. Your sales calls live in Gong. Customer feedback is in Zendesk. Product docs are in Confluence. Internal knowledge is scattered across Slack threads nobody will ever find again. The pattern transfers directly. And here's what Gong's built-in AI won't tell you: your tools analyze within their silos. None of them give you a unified, quality-tiered, cross-source knowledge base.
23,442 utterances is modest by enterprise standards -- a mid-stage SaaS company generates more content from sales calls in a single quarter. But the architecture scales to 100K+ records without rearchitecting. Sacred texts require attribution rigor that most enterprise data doesn't, which means if the architecture handles this, it handles your Gong calls.
The Extraction Pipeline -- One Base Class, Six Extractors
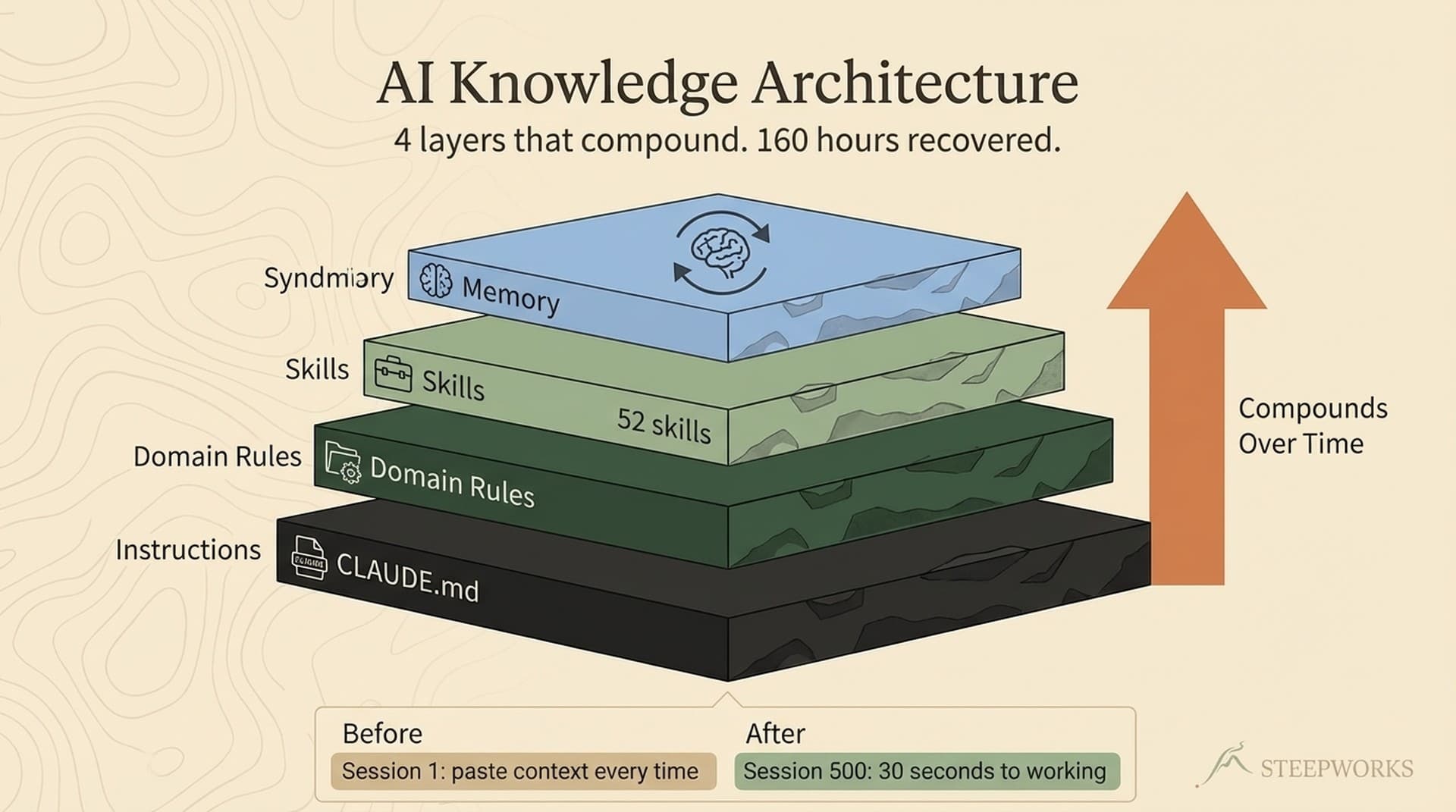
The architecture started with a contract. A Python base class -- base_extractor.py -- that defined what every extractor must output: the same utterance schema. ID, leader, source reference, original-language text, English translation, attribution marker, speech type, confidence tier, confidence rationale, context, and metadata. Twelve fields. Non-negotiable.
Six child classes inherited from that base, each solving a different parsing problem.
Muhammad was the easy one. 21,678 hadith records already structured as JSON. The grading system was built into the source data -- Sahih (sound), Hasan (good), Da'if (weak). Map those to TIER_1, TIER_2, TIER_3. Normalize the metadata. Done.
Jesus was different. Tab-separated Greek New Testament data with morphological codes. First challenge: red-letter detection -- finding where Jesus is actually speaking versus narrator commentary. Second challenge: Synoptic parallels. The same saying appears in Mark, Matthew, and Luke. That's not three utterances -- it's one utterance with multiple attestation, which actually boosts confidence. I mapped multiple attestation to a TIER_1 confidence boost. 163 utterances after deduplication.
Buddha had clean structured data -- bilingual JSON from SuttaCentral -- but spread across thousands of small files in a nested directory structure. The parsing challenge was identifying direct speech versus narrator commentary, which required pattern matching on Pali attribution markers like "bhikkhave" (monks) that signal the Buddha is addressing his followers. 796 utterances from the early strata.
Confucius arrived as plain text. Legge's 1893 translation from Project Gutenberg. No structure, no metadata, no API. I segmented by book, then by passage, then determined which passages are Confucius speaking versus his disciples versus the narrator. Books 10 and 19 got excluded -- Book 10 describes ritual behavior (Confucius didn't say those things, he did them), Book 19 is disciple speech. 332 utterances after filtering. The late Analects (Books 16-18, 20) flagged as TIER_3 due to scholarly consensus on later additions.
Laozi presented a different challenge. The entire Dao De Jing is attributed to Laozi, so the question isn't "did he say this?" but "when was this written?" The Guodian bamboo strips -- discovered in a tomb dating to approximately 300 BCE -- represent the earliest surviving text, so those passages got TIER_1. Everything else maps to TIER_2. Every entry flagged with metadata.historicity: "debated" because the historical existence of Laozi is an open question. 235 utterances.
Zoroaster was the ugliest parse and the cleanest scholarly situation. HTML scraped from Avesta.org -- Mills' 1887 translation. Inconsistent HTML, legacy formatting. But the Gathas -- 17 hymns -- are the oldest and most securely attributed Avestan text. All 238 utterances mapped to TIER_1. Painful parsing; straightforward confidence assignment.
The base_extractor pattern is the same one you'd use for ingesting sales calls from Gong, support tickets from Zendesk, and Slack threads. One schema, multiple parsers. The base class took an afternoon. The per-leader extractors took about two weeks. If your sources are more uniform -- and they probably are, since JSON APIs from SaaS tools are more consistent than 1887 translations of Zoroastrian hymns -- your extraction phase will be faster.
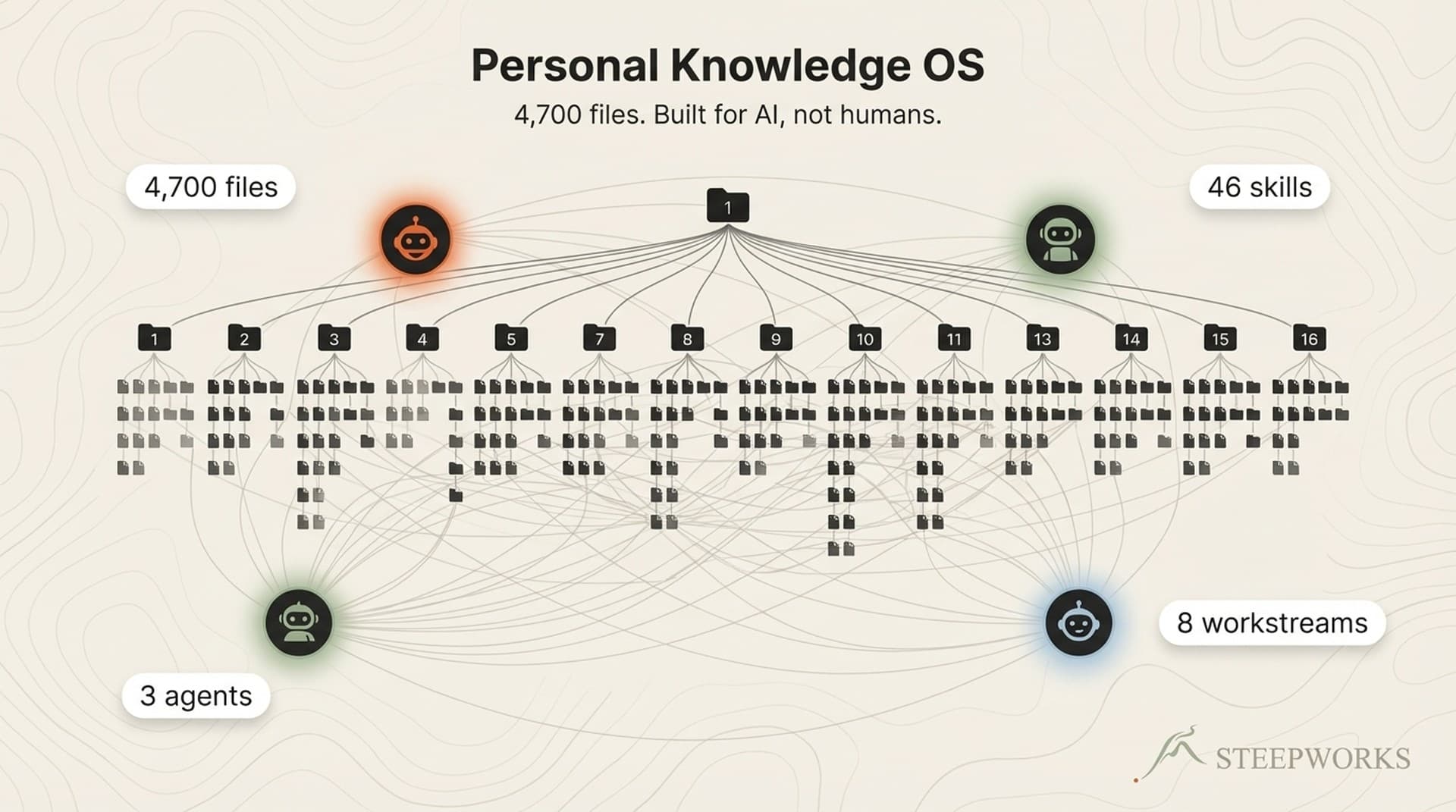
Related reading: I used a similar heterogeneous-ingestion pattern when I built a knowledge operating system from 4,700 files.
Confidence Tiering -- The Decision That Changed Everything
This design decision made every downstream system trustworthy. Not the schema. Not the query layer. The confidence tiers.
Three levels, each with explicit criteria grounded in each tradition's scholarly standards:
TIER_1 -- 42% of corpus, 9,707 utterances. Highest scholarly confidence. Earliest manuscripts, multiple attestation, broad consensus. For Muhammad: Sahih-graded hadith from Bukhari and Muslim. For Jesus: Synoptic core with multiple Gospel attestation. For Buddha: Dhammapada and earliest strata of the Sutta Nipata. For Zoroaster: all 238 Gatha utterances. For Laozi: passages attested in the Guodian bamboo strips.
TIER_2 -- 58% of corpus, 13,469 utterances. High confidence but secondary sources or later redaction layers. For Muhammad: Hasan-graded hadith. For Jesus: single-Gospel attestation. For Confucius: middle-period Analects (Books 1-2, 11-15). For Buddha: later Nikaya texts. For Laozi: received Dao De Jing text not attested in Guodian.
TIER_3 -- less than 1% of corpus, 28 utterances. Lower confidence, late additions, debated authenticity. All 28 are Confucius, from the late Analects (Books 16-18, 20). I excluded weak material entirely rather than carrying it at low confidence. The Dao De Jing's debated historicity gets handled through the metadata flag, not TIER_3 demotion.
When a downstream AI agent quotes the corpus, the confidence tier determines the response pattern. TIER_1 becomes DIRECT_QUOTE -- the agent cites the specific source and uses the actual words. TIER_2 becomes CORPUS_INFERENCE -- "Given my writing on X and Y, I would say..." TIER_3 becomes VOICE_EXTRAPOLATION -- "I haven't written about this directly, but based on my broader thinking..."
That graduated response is the difference between an AI agent that speaks with warranted authority and one that fabricates with false confidence.
Now imagine your AI sales copilot telling a prospect "our customers report 40% improvement in pipeline velocity" -- based on an unverified Slack message from 2023. That's what happens without confidence tiering. A recorded, transcribed call where the prospect explicitly states a pain point -- that's TIER_1. An AE's notes summarizing from memory -- TIER_2. A Slack rumor -- TIER_3. If you don't tier your data, your AI treats a Slack rumor with the same authority as a direct quote.
Quality validation confirmed the tiering held up. Buddha scored 99/100. Muhammad 97. Confucius 96. Zoroaster 95. Laozi 93. Jesus scored 72 -- missing Matthew chapters 5-7, the Sermon on the Mount. The most-quoted passage in Christianity wasn't in my corpus. That's the kind of gap only a validation protocol catches.
Search Infrastructure -- From Flat Files to Queryable Wisdom
Once you have 23,442 normalized, confidence-tiered utterances, you need to make them searchable. Not grep-searchable. Semantically searchable, cross-tradition, filtered by quality.
I built a Python class called PropheticCorpus with methods that reflect how I actually wanted to query: search, compare_themes, search_by_theme, tag_themes, get_stats, export_filtered. The entire corpus fits in memory. No database.
The question I kept getting: why not a vector database? (Knowledge OS guide)
Because 23,442 utterances is small enough that keyword search with a curated thematic taxonomy outperforms embeddings. I tried both. The taxonomy-based search returned more relevant results because the themes are domain-specific -- LOVE_COMPASSION, TRUTH_HONESTY, SUFFERING_IMPERMANENCE, 16 themes total, each designed to bridge linguistic and conceptual gaps across six traditions. Generic embeddings didn't understand that "dukkha" and "suffering" and "the problem of pain" are the same concept in Pali, English, and Christian theological vocabulary. (See also: knowledge graph)
My rough breakpoint: below ~50,000 records with strong domain vocabulary, a curated taxonomy wins on relevance. Above that, you need embeddings -- or both. (See also: compound knowledge)
The thematic taxonomy was the most labor-intensive part. Not engineering -- domain study. Three weeks of reading source texts, mapping conceptual overlaps, refining category boundaries. NLP topic modeling would have been faster but would have produced generic categories that miss theological nuance. "Justice" in the Hebrew prophetic tradition and "justice" in Confucian thought overlap but aren't identical.
Cross-tradition comparison was the payoff. corpus.compare_themes(["forgiveness"]) returns how all six leaders address the concept -- different language, different frames, different theological commitments, searchable in one call. This is the same pattern as building a searchable knowledge base from sales calls. You don't need a vector database for 500 call transcripts. You need good taxonomy, consistent schema, and a query layer that understands your domain. Google Cloud's RAG corpus management documentation shows the enterprise-scale version. (Claude for operators)
How the Corpus Powers AI Agent Dialogue
The corpus feeds five AI dialogue agents, each grounded in published scholarly writings, plus a routing orchestrator and a roundtable moderator for multi-voice discussion.
The companion article -- I Turned 5 Rabbis Into AI Agents -- covers the agent architecture. Here I want to focus on how confidence tiers flow into agent behavior.
TIER_1 feeds DIRECT_QUOTE responses -- specific source citation, actual words. TIER_2 feeds CORPUS_INFERENCE -- "Given my work on interfaith dialogue, I would approach this by..." TIER_3 feeds VOICE_EXTRAPOLATION -- "I haven't written about this directly, but based on my broader theological commitments..."
This graduated response prevents voice drift -- agents hallucinating teachings or drifting into each other's voices. Without the confidence-tiered corpus as anchor, these agents would be personality prompts floating on generic language model tendencies. With it, they're grounded in verifiable source material.
The system also maintains an agent memory layer -- effective formulations, bridge vocabulary, engagement patterns -- stored per faculty member. The corpus is extracted once and stable. The agent memory grows with use. Two different rhythms of knowledge: one archival, one adaptive.
If you're building customer-facing AI agents -- product assistants, sales copilots, support bots -- the quality of your underlying corpus directly determines trustworthiness. An untiered knowledge base produces an agent that speaks with false confidence about unreliable data.
Quality Validation -- The Part Everyone Skips
I built the validation protocol after the corpus was complete. That was a mistake. It should have been a gate during extraction.
Each sub-corpus was scored against five dimensions: coverage completeness, attribution accuracy, schema compliance, confidence tier distribution, and source documentation. Scores out of 100. (course vs done-for-you comparison)
Five of six passed above 93. The outlier: Jesus at 72/100. The gap -- Matthew chapters 5-7, the Sermon on the Mount -- wasn't in the extraction. The most-referenced passage in Christianity, missing entirely. Not because the source data was unavailable, but because the extraction pipeline hadn't been configured to pull from that section. (DIY vs professional setup)
That gap is invisible without a validation protocol. The corpus had 163 Jesus utterances. It looked complete. The tiering was correct. The schema was clean. A simple coverage check against known major textual units revealed the hole. (Claude Code alternatives comparison)
Most organizations skip this when building AI knowledge bases. They dump documents into a vector store and call it done. Then the AI confidently cites an outdated policy or a draft that was never approved. Validation is the difference between a system people trust and one they route around. Research on RAG and enterprise knowledge management consistently finds that quality validation is the strongest predictor of sustained adoption. (when to implement Claude Code)
The Transfer Pattern -- Your Organization Has 23,442 Utterances Too
| Corpus Engine | Enterprise Knowledge |
|---|---|
| 6 spiritual traditions | Sales calls, support tickets, Slack, docs |
| Per-leader extractors | Per-source parsers (Gong API, Zendesk export, Confluence API) |
| Utterance schema | Unified knowledge record |
| Confidence tiers | Data quality tiers (verbatim transcript, AE notes, Slack hearsay) |
| Thematic taxonomy | Domain-specific topic categories |
| PropheticCorpus query layer | Internal search API |
| AI dialogue agents | Customer-facing assistants, sales copilots |
| Quality validation | Accuracy audits, coverage checks |
The objection I hear most: "I already have Gong AI. HubSpot summarizes my deals. Slack has search. Why do I need a corpus engine?" (what professional setup includes)
Try this: ask "what do our customers say about pricing?" and get a single answer that draws from your recorded calls, support tickets, Slack conversations, and product feedback -- weighted by source quality. You can't. Each tool's AI operates in its silo. The corpus engine is the cross-silo layer -- a unified schema that lets you search across sources, filtered by confidence tier and topic. It's not replacing Gong. It's the connective tissue between Gong, HubSpot, Zendesk, and Slack that doesn't exist today. (why Claude Code feels too hard)
Companies spent $37 billion on generative AI in 2025, up from $11.5 billion in 2024. Most of that investment sits on unstructured, untiered knowledge bases. The corpus engine is the missing layer between raw data and AI applications. (Knowledge OS explained)
What most teams get wrong: they start with the AI agent -- the chatbot, the copilot, the assistant. Then they wonder why it hallucinates. They should start with the corpus. The agent is the straightforward part. The quality of the underlying data determines everything. (context engineering deep dive)
Where to start:
- Pick one source -- probably recorded sales calls or support transcripts. (how to evaluate a consultant)
- Build one extractor that normalizes into a consistent schema. Twelve fields: ID, source, speaker, text, topic, confidence tier, confidence rationale, context, timestamp, and domain metadata.
- Define your confidence tiers. Verbatim quote from a recorded call? Secondhand notes? Slack hearsay? Name them and enforce them.
- Validate coverage. What's missing? What major topic or customer segment has no representation?
- Build the query layer. Search, filter by tier and topic, export subsets.
- Then put an AI agent on top.
Two to three weeks of engineering time for steps 1-5 with a single source. You don't need a team. You need one engineer who understands your data.
What I'd Do Differently
What worked. The base_extractor pattern -- one contract, six implementations -- paid for itself immediately. Confidence tiering as a first-class design decision made every downstream integration cleaner. The hand-curated taxonomy outperformed automated topic modeling at this scale. The validation protocol caught the Sermon on the Mount gap.
What I'd change. Start with embeddings AND taxonomy in parallel. Keyword search works at 23K utterances but won't scale gracefully past 100K. Both have strengths -- taxonomy gives precision, embeddings give recall on unexpected connections -- and combining them beats choosing one.
Build validation before extraction, not after. Running it as a gate catches gaps in real time. The Sermon on the Mount gap would have surfaced weeks earlier.
Invest more in bilingual support from the start. Only Muhammad and Buddha have original-language text alongside English. Confucius deserves the Chinese Analects. Laozi deserves the Chinese Dao De Jing. Zoroaster deserves the Avestan. Original-language text opens philological analysis that translations can't support.
What's next. Semantic search with embeddings layered on the existing taxonomy. A web interface (current access is CLI-only). Remediating the Jesus corpus with Matthew 5-7. Expanding the Buddha corpus, which currently samples from a much larger collection.
The corpus engine pattern isn't specific to sacred texts. It's a knowledge infrastructure pattern. If your organization has institutional knowledge worth preserving -- customer conversations, product decisions, competitive intelligence -- this is how you make it trustworthy enough to power AI.
The hard part was never the code. It was data modeling, confidence decisions, and the patience to validate before declaring it finished. Stanford's work on text classification evaluation has been saying this for years.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.