title: "Multi-Agent AI Coordination: 5 Agents, 1 Repo" slug: branch-safety-multi-agent seo_keyword: "multi-agent AI coordination" meta_description: "Multi-agent AI coordination failure: one agent ran git checkout, four others lost work. A 4-layer safety architecture from 3 incidents in 5 days." og_description: "5 AI agents, 1 repository, zero coordination. One branch switch destroyed 14 phases of work. Here's the 4-layer architecture that prevents it with encoded protocols." cluster: claude-code-operators author: Victor status: published published_date: 2026-03-25 read_time_minutes: 11 description: "Multi-Agent AI Coordination: 5 Agents, 1 Repo" domain: steepworks type: article updated: 2026-03-25
Multi-Agent Coordination in a Shared Working Tree: Patterns from Running 5 AI Agents on One Repository
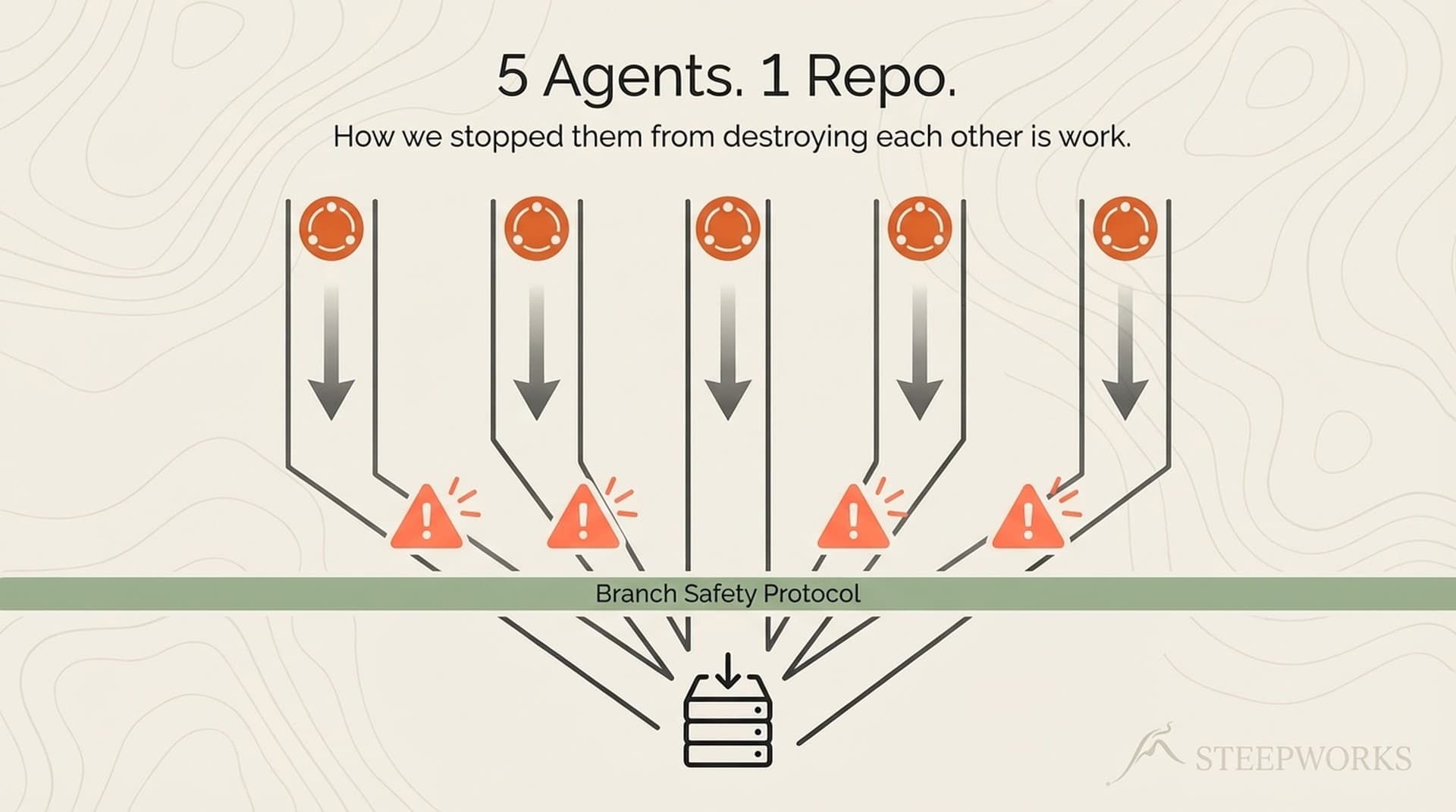
Five AI agents. One repository. Zero coordination layer between them.
On March 20, 2026, one agent ran git checkout to inspect earlier work while the other four were mid-task. Fourteen phases of newsletter migration work vanished. No error message. No warning. Just an empty working tree where hours of uncommitted files used to be.
I stared at git status output showing a clean tree. The files weren't corrupted or conflicted — they were gone. A branch switch replaces the entire working tree state. If four other agents have uncommitted work across dozens of files, that work ceases to exist the instant the fifth agent switches branches.
That incident reframed something I'd been thinking about wrong. The hard problem in multi-agent AI isn't making agents smarter. It's making agents coexist. When you run multiple autonomous AI coding agents against a single repository — each reading, writing, staging, and committing — you hit coordination failures that no single-agent workflow prepares you for. The answer isn't an orchestration service or a message bus. It's encoded coordination protocols: rules files that every agent loads automatically, skills that standardize dangerous operations, and a shared instruction set that gives all agents the same mental model of what's safe.
If you're running one AI coding agent and thinking about adding a second, this is the field report. The failures aren't gradual. They're instant the moment two agents touch the same mutable state.
The Operating Context
I run three to five Claude Code terminals simultaneously against one repository — a 4,700-file knowledge operating system spanning 16 top-level directories and 8 workstreams. One terminal handles content production. Another runs newsletter data pipelines. A third builds website components. A fourth processes event scrapers. They share a single working tree.
These aren't copilot sessions where I review every action. Each terminal runs an autonomous agent that reads files, writes outputs, stages changes, and commits — independently, concurrently, with no awareness of what the others are doing. One agent might be mid-way through a 14-phase newsletter consolidation while another runs a routine code review. Neither knows the other exists.
The repo also supports three AI platforms: Claude Code (primary), Codex CLI, and Gemini (I sometimes also use Codex and Antigravity instead of VS Code). The coordination problem isn't just multiple terminals — it's multiple platforms sharing the same instruction set and working tree.
Standard developer tooling assumes one actor, one terminal, sequential operations. That assumption is baked deep. git stash assumes you'll pop it in the same session. git checkout assumes nobody else has uncommitted work. git add . assumes everything in the directory belongs to your current task. Every one of those assumptions breaks with a second concurrent agent.
Multi-agent coordination requires a different design surface: encoded rules agents load before touching anything, standardized skills wrapping dangerous operations, and a shared instruction hierarchy giving every agent — regardless of platform — the same model of what others have called "terminal hell".
The coordination surface: 50+ skills operating independently, 18 path-scoped rules files that auto-load based on context, and 3 AI platforms sharing one instruction hierarchy as the coordination backbone.
Three Coordination Failures in Five Days
The architecture wasn't designed upfront. It was extracted from three incidents in five days.
Failure 1 — Shared Mutable State (March 20)
A review agent switched branches to inspect earlier work. Four other agents were mid-task. The branch switch silently replaced the entire working tree, destroying fourteen phases of newsletter consolidation.
I want to be precise about what happened. The review agent's task was legitimate — it needed to compare output against a baseline. It ran git checkout to reach that baseline. The command succeeded. Git did exactly what it was told. The problem was structural: five agents shared mutable state, one agent mutated it, the other four had no mechanism to protect their in-progress work.
Root cause: no protocol prevented one agent from mutating shared state while others depended on it. Classic concurrent-write problem, expressed through git's working tree instead of a database.
Failure 2 — Implicit Dependency (March 21)
An agent converting 50+ skill files ran concurrently with a QA agent. The QA agent needed before-and-after comparison, so it switched branches. The conversion agent kept writing — but now to a different branch's working tree, producing corrupted output it couldn't detect.
This was subtler. The conversion agent didn't crash or throw errors. It kept working, writing files that looked correct in isolation but landed in the wrong context. I didn't notice until the conversion was "complete" and the output made no sense.
Root cause: agents had an implicit dependency on working tree state but no mechanism to declare or protect it.
Failure 3 — Missing Audit Trail (March 24)
Nine phases of SEO content generation committed directly to main. No work lost — everything landed where it should. But the audit trail was destroyed. Couldn't review phases independently, couldn't revert a single phase without reverting all nine, couldn't trace which changes came from which task.
Don't get me wrong — losing the audit trail hurts differently than losing work, but it still hurts. When running multiple agents on independent tasks, the ability to review, revert, and trace each agent's contributions separately is what makes the system governable. Without it, you have a black box.
Root cause: no protocol enforced the branch-per-task pattern that makes agent work independently reviewable.
The Stash Graveyard
Between incidents, I tried the obvious fix: stash before switching. Accumulated 36 orphaned stashes in one week. Each stash is a snapshot of mid-task state with no context — which task, which branch, whether contents are still relevant. Stashing is a workaround for sequential workflows. It's not a coordination mechanism for concurrent agents.
The Coordination Architecture — Four Layers
After those five days, I built four layers, each solving a different class of conflict.
Layer 1: Shared Instruction Set. The top-level instruction files give all agents the same mental model of the repository, structure, and conventions. Every agent reads the same rules, same workstream routing, same session recovery protocol. Three AI platforms read from this same hierarchy. This is the constitution layer — establishes shared context that makes all other coordination possible.
Layer 2: Auto-Loading Rules. Eighteen domain-specific rule files load automatically based on which files an agent touches. Each has YAML frontmatter with a paths: field controlling scope. paths: [] means universal — loads for all operations. paths: ["14_newsletters/**"] loads only for newsletter files. Rules encode prohibitions, safe alternatives, and the reasoning behind each constraint.
Layer 3: Standardized Skills. Fifty-plus skills wrap dangerous operations into guardrailed workflows. The push-pr skill enforces branch creation, selective staging, safety checks, and PR creation as a single atomic workflow. Skills are the safe API layer: agents invoke a skill instead of running raw git commands.
Layer 4: Branch Safety Protocol. Four rules derived from the three incidents, encoded in a universal rules file loading for every operation. This is where coordination meets enforcement.
Each layer reinforces the others. The instruction set says "always use push-pr." The skill enforces "always create a branch." The rules prohibit switching to an existing branch. Auto-loading ensures agents can't skip any of it.
How Rules Files Encode Coordination
Rules in .claude/rules/ use YAML frontmatter with a paths: field. The branch-safety rules use paths: [] — load for every operation, every file, every directory. That's how you encode a universal constraint no agent can skip.
Phrasing matters more than you'd expect. I learned through iteration. "Prefer creating new branches" doesn't work — agents treat soft language as optional and make their own calls. "NEVER switch to an existing branch" works. Absolute language for dangerous operations: NEVER, Do NOT, CRITICAL. Affirmative language for approved alternatives: SAFE, allowed, expected. Not dramatic — just unambiguous.
Every prohibition pairs with a safe alternative. The rule banning git checkout [existing-branch] is immediately followed by git checkout -b [new-branch] as the approved operation. Agents that only know what's forbidden make unpredictable substitutions. Agents that know the approved path follow it consistently. (See also: claude md)
The rules also include a "Why These Rules Exist" section with dated incidents. Agents that understand the reasoning apply rules more correctly in edge cases. When a prompt says "quickly check main branch for that file," an agent that's read about the March 20 incident finds an alternative (like git show main:path/to/file) rather than running the bare prohibition.
Here's the coordination rules template — strip the repo-specific paths and this transfers to any multi-agent setup. (See Anthropic's docs for the rules file format.)
# Branch Safety Rules (UNIVERSAL)
---
paths: []
description: Multi-agent coordination — branch+PR workflow, never switch branches
---
## Rule 1: NEVER Commit Directly to Main
Every piece of work gets: branch -> commit -> push -> PR -> merge.
## Rule 2: NEVER Switch to an Existing Branch
Do NOT run: git checkout [existing-branch] or git switch [existing-branch]
SAFE: git checkout -b [new-branch] / git switch -c [new-branch]
Exception: git checkout -- [file] (restoring a single file) is allowed.
Why: Multiple agents share one working tree. Switching destroys uncommitted work.
## Rule 3: Once Merged, Never Reuse a Branch
New work = new branch = new PR.
## Rule 4: Stage Immediately After Writing
After batch operations (3+ files), git add immediately.
Protects against work loss from concurrent agents.
## Why These Rules Exist
[Include dated incident log. Agents that understand reasoning
apply rules more correctly in edge cases.]
Eighteen rules files follow this pattern, each scoped to specific file patterns. The coordination protocol scales by domain without bloating any single instruction file.
Skills as Coordination Mechanisms
Rules tell agents what not to do. Skills tell agents how to do things safely. The push-pr skill is the clearest example — a coordination mechanism, not a convenience wrapper.
Six steps, each enforcing a constraint:
Assess. Read current state: branch, staged files, modifications. Prevents acting on stale assumptions. In a multi-agent environment, tree state might have changed since the agent last checked.
Safety scan. Check for sensitive files, verify pre-commit hook awareness. One agent shouldn't commit another's environment files.
Branch. Always create a new branch from HEAD. Every agent's work gets its own branch, its own PR, its own reviewable history.
Stage selectively. Stage files by name, never git add -A. A blanket stage captures another agent's uncommitted work in your commit. Selective staging scopes each commit to its own task.
Commit with attribution. Descriptive message with Co-Authored-By. With multiple agents producing commits, traceability is how you audit which agent introduced which changes.
Push and PR. Always create a PR. The PR is the audit unit for reviewing each agent's work independently.
The instruction file mandates: when the operator asks to commit, push, stage, or create a PR, invoke push-pr. No raw git commands for state-changing operations.
The skill is ported across platforms using a reference-not-copy pattern — thin redirect pointing to the canonical definition. Three platforms, one protocol, same behavior. When I set up Claude Code for a GTM team, push-pr is one of the first things I install.
Why Worktrees Weren't the Answer (And When They Are)
The standard recommendation is git worktrees — each agent gets its own directory with its own branch. They eliminate shared mutable state entirely. For code repositories with self-contained feature branches, worktrees are correct. The Nx team's write-up on their multi-agent worktree adoption is sound.
For a knowledge operating system, worktrees fragment coherence. The 50+ skills reference shared context by relative path. Session recovery assumes a single working directory. The knowledge graph cross-references files across all 16 directories. Separate worktrees would require rewriting every relative path or maintaining synchronized copies. The cure would be worse than the disease.
Worktrees win when: team repository, microservice architecture, agents operating on isolated slices.
Coordination protocols win when: single operator with multiple agents on a knowledge system, monorepo with cross-referencing files, shared context as a feature not a bug.
Neither is universally correct. Community consensus leans toward worktrees, and for most code repos that's right. But "use worktrees" assumes independent features, and not every repository fits that model.
What This Looks Like in Practice
Zero work-loss incidents from agent coordination since adopting the architecture on March 24. Short track record — I'm writing this one day later. But the specific failure mode that destroyed work three times in five days hasn't recurred. The architecture addresses root cause (uncoordinated shared state mutation), not symptoms.
PR history shows clean phase separation. Each agent's work is independently reviewable. I can trace which agent introduced which changes, revert a single phase, and audit the decision trail through PR descriptions.
Stash accumulation stopped. No more "preserve dirty state" workarounds. The 36-stash graveyard was the clearest signal the old approach wasn't working.
What's still fragile: file-level merge conflicts when two agents edit the same file concurrently. The architecture prevents branch-level destruction but not content-level collisions. That's the next problem. Likely file-level advisory locks or task-scoped file ownership declarations. I'd rather ship what works and solve the next problem when I hit it.
The architecture also depends on instruction-following fidelity. A model update changing how rules get prioritized, or a context window truncating the safety rules, could weaken guardrails. This is rule-based coordination, not a locking mechanism. It works because current-generation models follow well-phrased absolute prohibitions reliably. If that changes, the architecture needs a harder enforcement layer.
Coordination Is the Hard Problem
Community consensus for multi-agent coordination leans toward more infrastructure: orchestration layers, message buses, worktrees, coordination services. Valid for team contexts. But for a single operator running multiple AI agents, the simpler pattern is encoded protocols — rules agents load automatically, skills wrapping dangerous operations, a shared instruction set.
The four-layer architecture didn't require new tooling. It used capabilities already in Claude Code's rules and skills system. The coordination is in the content of the configuration, not additional infrastructure. I didn't install anything new. I wrote markdown files with YAML frontmatter and put them in the right directories.
The pattern generalizes beyond git. Any shared mutable resource — database connections, API rate limits, file system writes, deployment pipelines — can be protected by encoding coordination protocols into agent instruction sets. Anywhere multiple agents touch the same state, the same design surface applies: prohibit the dangerous operation, provide the safe alternative, explain why, make it load automatically.
If you're hitting coordination failures with multiple AI agents, start with encoded protocols before reaching for orchestration tooling. The constraint might be the solution.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.