title: "AI Sales Enablement: Deal Health Check in 4 Min" slug: deal-health-check-4-minutes seo_keyword: "AI sales enablement" meta_description: "AI sales enablement: 7% of orgs hit 90%+ forecast accuracy. A 5-step skill chain scores 10 MEDDPICC dimensions and flags zombie deals in 4 minutes." og_description: "A 5-step AI skill chain runs a deal health check on every open deal in 4 minutes: CRM pull, 10-dimension scoring, zombie detection, coaching notes, 3-layer output. Found $340K in phantom pipeline on one team." cluster: ai-for-gtm author: Victor status: published published_date: 2026-03-25 read_time_minutes: 11 description: "AI Sales Enablement: Deal Health Check in 4 Min" domain: steepworks type: article updated: 2026-03-25
How I Run a Deal Health Check in 4 Minutes -- The RevOps Skill Chain
The Pipeline Review Nobody Has Time For
Every sales leader I know has the same weekly ritual. Open the CRM. Click into the first deal. Ask the rep: "So what's happening with this one?" Listen to two minutes of narrative. Nod. Click the next deal. Repeat thirty times.
An hour later, you walk out knowing roughly what you knew going in -- which deals the rep is excited about, which ones they're avoiding, and nothing quantitative about pipeline health.
I ran these meetings for years. Reps narrate the story they want to be true. Close dates slide right. The "next step" field says "follow up" on twenty of thirty deals. The meeting ends with a gut feeling that's maybe 60% correlated with reality.
The data backs this up. According to Spotlight.ai's 2026 forecasting research, only 7% of sales organizations achieve 90%+ forecast accuracy. The median sits at 70-79%. That gap isn't a tool problem. It's an inspection problem. Rigorous inspection takes too long to do manually.
So I asked: what if I could run a rigorous deal health check on every open deal -- not in an hour, but in four minutes?
Not a dashboard. Not a chatbot. A structured diagnostic that pulls CRM data, scores ten dimensions, flags zombie deals, and produces coaching notes I can walk into a one-on-one with. Four minutes, every deal, every week.
What a Skill Chain Is (And Why It Matters More Than the Tools)
Search "AI sales enablement" and you'll find listicles evaluating tools in isolation. Gong for call intelligence. Clari for forecasting. Seismic for content management. Each review treats the tool as standalone.
That framing misses where the value lives.
A skill chain is a sequence of operations where each step's output becomes the next step's structured input. Not a dashboard. Not a single tool doing one thing. A pipeline of linked operations that produces a compound result no individual step could produce alone.
The deal health chain has five links:
- Pull -- Query CRM for open deals, contacts, and activity data
- Score -- Rate each deal across 10 MEDDPICC dimensions on a 100-point scale
- Detect -- Run zombie detection and stage validation against heuristic signals
- Coach -- Generate stall diagnoses and specific recommended actions
- Render -- Output a structured report in three layers: CRO summary, manager detail, rep actions
The scoring step doesn't just produce a number and stop. Zombie detection reads the scoring output. Coaching notes read both scores and zombie signals. The three-layer output reads everything. Each link adds intelligence because it has access to what came before.
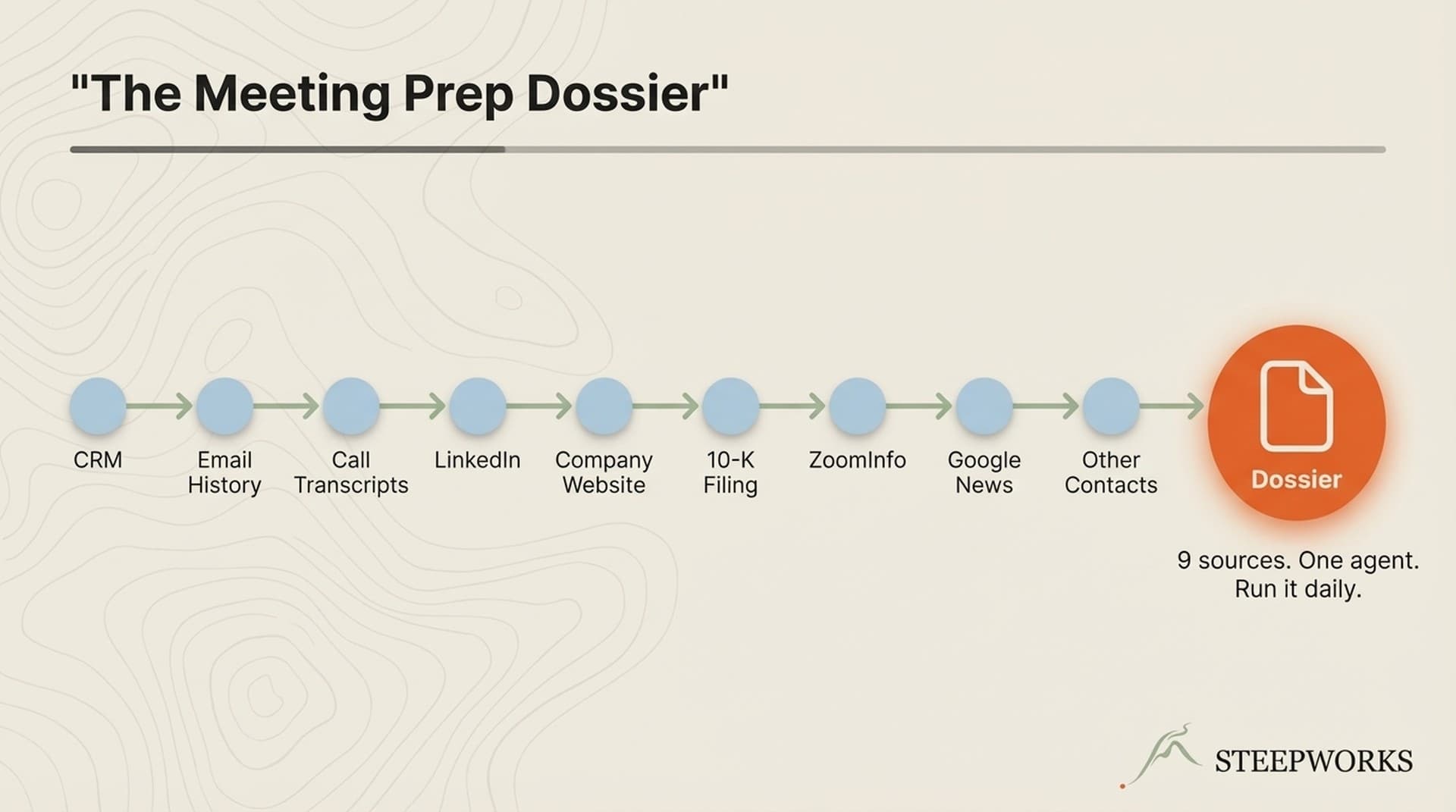
I wrote about this composable architecture in The AI GTM Stack I Actually Use: 14 Tools, 3 Integrations, 1 System. And if the "systems over individual tools" thinking resonates, I unpacked it in Why Most Teams Fail at Month 3.
The 4-Minute Breakdown -- Step by Step
Four minutes is the real number on a 30-deal pipeline. At 100+ deals, the pull step stretches to 2-3 minutes and the whole chain runs 8-10 minutes. Still beats an hour of manual review.
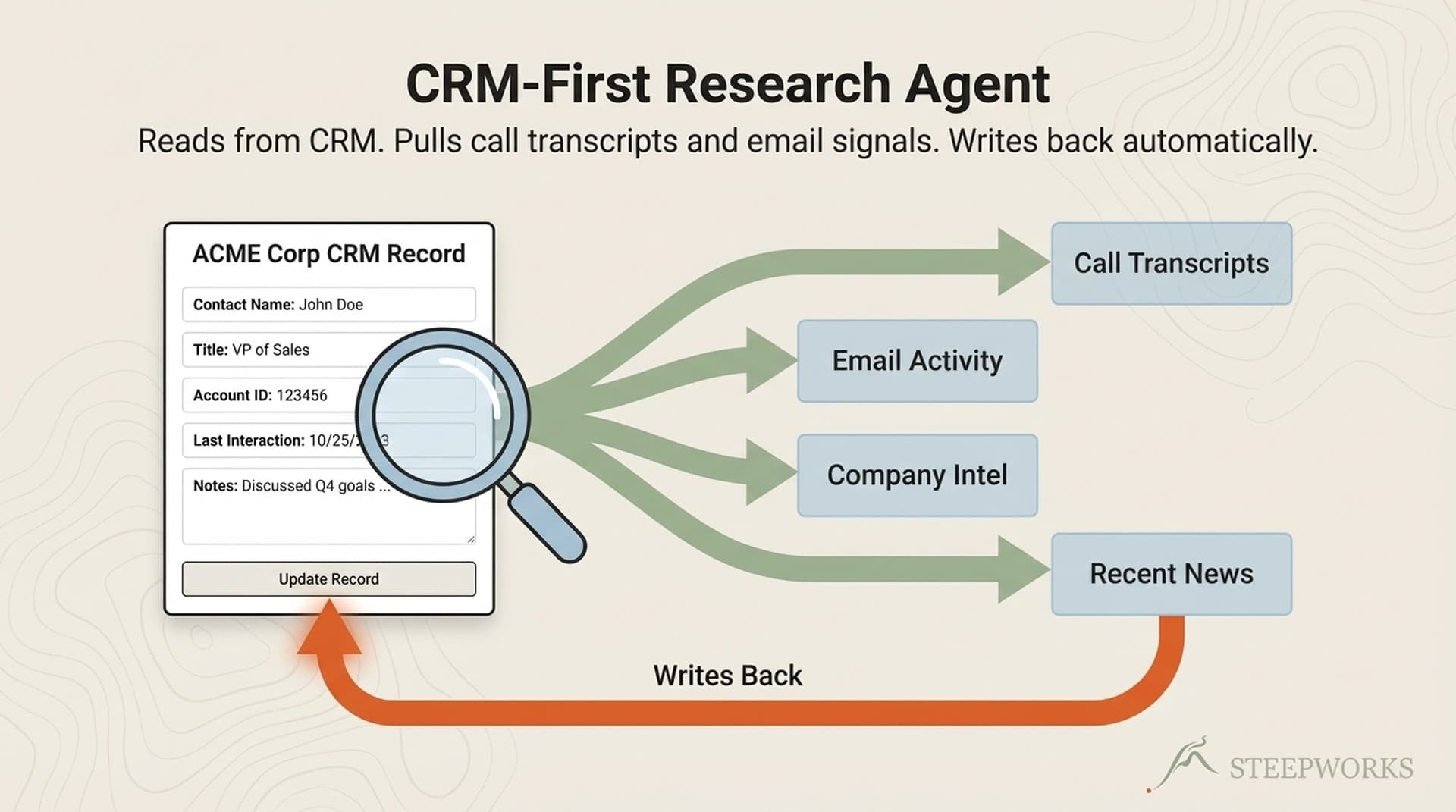
Minute 0-1: CRM Data Pull
The chain queries the CRM for every open deal -- ten fields per deal: name, stage, amount, close date, owner, last modified, last activity, next step, contact count, and create date.
Then it fetches associated contacts and maps them to MEDDPICC roles by job title. A VP of Procurement becomes an Economic Buyer. A Director of Engineering who's been your internal advocate becomes a Champion. A CFO gets tagged as Decision Maker. Title-to-role is always an approximation, but it produces a contact coverage map that's directionally accurate and far better than what most pipelines have.
It also pulls recent activity: calls, emails, meetings from the last 90 days. From this, it computes days since last activity, engagement trajectory (accelerating or decelerating?), and four-week frequency trends.
On 30 deals with ~3 contacts each, this step takes 45-60 seconds. Mostly CRM API pagination.
Minute 1-2: 10-Dimension Scoring
Each deal gets scored across ten dimensions:
| Dimension | Points | What It Measures |
|---|---|---|
| MEDDPICC Quality | 15 | Completeness of methodology fields |
| Activity Pattern | 15 | Recency, frequency, trend of engagement |
| Multi-Threading Depth | 15 | Number and diversity of contacts by role |
| Stage Velocity | 10 | Days in current stage vs. median benchmark |
| Champion Strength | 10 | Champion identified, active, recently engaged |
| Close Date Credibility | 10 | Is the close date physically achievable? |
| Deal Momentum | 10 | Stage advances, activity trend, close date stability |
| Next Step Quality | 5 | Specific and time-bound vs. "follow up"? |
| Economic Buyer Access | 5 | EB identified and engaged? |
| Competitive Position | 5 | Competition tracked and addressed? |
Each dimension has an explicit calculation. Stage Velocity compares days in current stage against a median benchmark from your own closed-won history. A deal at 3x the median scores zero. A deal at 0.5x scores the full 10 points.
The scoring runs on structured CRM data. No LLM hallucinating about deal sentiment from email tone. If the data says one contact, no next step, and a close date pushed three times, the score reflects exactly that.
70+ means strong fundamentals. 40-69 means specific gaps. Below 40, the deal probably shouldn't be in the pipeline at its current stage.
Minute 2-3: Zombie Detection and Stage Validation
This is where the chain earns its keep.
Ten heuristic signals, each weighted:
- No logged activity for 14+ days
- Close date pushed 3+ times
- Champion gone silent (21+ days)
- Stage duration at 2x benchmark median
- Single-threaded in a late stage (one contact at Proposal or later)
- No Economic Buyer engagement for 60+ days
- Zero associated contacts
- Next step blank or generic ("follow up," "check in")
- Deal amount decreased twice
- Create date older than 2x average sales cycle with no stage advance in 30 days
Three or more weighted signals: ZOMBIE. Five or more: DEAD. The language is deliberate. "At risk" and "needs attention" let people defer action. Zombie and dead force a disposition decision: resuscitate with a specific plan in seven days, or close it out.
Stage validation runs in parallel. Does this deal actually have the evidence to be at its current stage? A deal at Proposal with no Economic Buyer and one contact gets flagged Stage-Inflated.
The most valuable single check: the Close Date Credibility Gate. It computes minimum days to close based on remaining stages and historical velocity. A deal in Discovery with a 30-day close date, when the median Discovery-to-Close path is 90 days across three stages -- that's not aggressive. It's fantasy. Tagged FANTASY, excluded from forecast commit.
I've never run this on a pipeline and found fewer than 15% of deals carrying impossible close dates. Often 25-30%.
Minute 3-4: Coaching Notes and Structured Output
Every stalled or zombie deal gets one of eight stall diagnoses:
- No Activity -- No engagement in 14+ days
- Champion Gone Silent -- Primary champion hasn't responded in 21+ days (done-for-you implementation)
- Blocked by Procurement -- Stuck in late stage with procurement-related notes (See also: meeting prep agent)
- Wrong Stage -- Evidence doesn't support current stage (See also: deal health agent)
- Budget Frozen -- Signals of budget hold or delayed approval (See also: workflows)
- Decision Delayed -- Active deal but timeline pushed
- Competition Active -- Competitor engagement detected, deal stalled
- Missing Info -- Key MEDDPICC fields empty
Each diagnosis comes with a specific action. Not "triage this deal." Not "re-engage or close." Something like: "Schedule multi-thread meeting with VP Engineering by Friday" or "Send budget justification doc to Economic Buyer within 48 hours." (pricing tiers)
Output renders in three layers:
Layer 1 -- CRO Executive Summary: Total pipeline (reported vs. real after zombie removal), coverage ratio (reported vs. real), zombie count and dollar value, momentum trending up or down, top three deals by risk.
Layer 2 -- Manager Detail: Per-deal breakdowns, stage validation flags, stall diagnoses, zombie signals, close date credibility. The view you walk into a pipeline review with.
Layer 3 -- Rep Action Items: Prioritized by urgency with specific deadlines. No deal-level analysis -- just "here's what you do this week, in order."
A CRO doesn't need deal-by-deal MEDDPICC scores. A rep doesn't need coverage ratios. Same data, three views, three sets of actions.
Three Deals the System Caught That Humans Missed
The "Sure Thing" With Zero Multi-Threading
An $85K enterprise deal in Proposal stage for 22 days. Rep reported it as "90% likely to close this quarter." Manager had no reason to push back.
The chain found: single-threaded. One contact, an IC. No Economic Buyer. No stage advance in 40 days. Next step blank. Score: 31/100. Zombie signals: 4.
The rep was anchoring on a conversation from six weeks ago with a champion who had gone quiet. Reason: an org restructure moved them to a different division. The deal wasn't at risk -- it was functionally dead.
The manager intervened, discovered the restructure, and re-qualified at roughly a third of original size with a new contact path. Without the chain, that $85K would have sat in commit forecast until the quarter closed.
The Fantasy Close Date
A $120K mid-market deal with a close date 18 days away, end of quarter. Rep had it in commit. On paper, fine.
Close Date Credibility: 0/10. The deal was in Evaluation. Median path from Evaluation through three remaining stages: 47 days. The rep had 18. Tagged: FANTASY.
This deal was 15% of the rep's committed pipeline. Removing it dropped real coverage from 2.1x to 1.4x -- "comfortably ahead" became "need significant new pipeline." The CRO pulled it from commit to best-case. It closed six weeks later, next quarter. The board call that month had an accurate forecast.
The Zombie Farm
Across a 35-deal pipeline: nine zombies totaling $340K in phantom pipeline.
Reported pipeline: $1.8M. Real pipeline after zombie and stage-inflation removal: $1.1M.
Reported coverage: 3.6x. Real coverage: 2.2x. That's "we're fine" versus "we need 40% more pipeline this quarter."
Three of nine had been in Discovery for 180+ days. The reps stopped working them months ago but never closed them out.
Within one week, all nine got forced dispositions. Three closed lost. Two transferred to prospecting for re-approach next quarter. Four got seven-day deadlines with clear criteria: no response by Friday, close lost.
The pipeline looked worse after cleanup. It was healthier -- every remaining deal was real.
What This Doesn't Replace
The chain doesn't replace Gong for call intelligence, Clari for executive dashboards, or Seismic for content delivery.
What it replaces: the manual pipeline review where a manager clicks through 30 deals, asks for narratives, gets stories that may or may not match reality, and walks away with a gut feeling.
The skill chain is a diagnostic. It runs, produces a structured report, and gets out of the way. The coaching conversation still happens human-to-human. The difference is the manager walks in with risk scores, zombie signals, stall diagnoses, and close date credibility instead of relying on rep narratives.
The build vs. buy tradeoff is real. If you have $40-80K/year for Clari, Momentum, or similar platforms, they do this plus dashboards, forecasting UI, and trend analysis. The skill chain makes sense for teams under $10M ARR who can't justify that spend, solo operators who want deep pipeline visibility, or anyone who wants to understand what these platforms compute before committing budget.
Building your own teaches you things buying can't. When you construct the scoring logic, you develop intuition for deal inspection that persists even after switching to a commercial platform.
The CRM Data Quality Trap
The most common pushback: "This only works if your CRM data is clean."
The framing is backwards.
The scoring doesn't require clean data. It requires data to exist or not exist. A deal with zero contacts, no next step, and a stale close date isn't "unscorable." It scores low -- and that low score IS the diagnosis. The absence of data is the signal.
If a rep hasn't logged activity in 21 days, that's not a data quality problem. That's a deal health problem. If there's no Economic Buyer at Proposal stage, the CRM isn't broken -- the selling motion is.
What happens in practice: the chain improves CRM hygiene as a side effect. When blank fields directly impact deal scores -- and managers see the same scores -- the incentive shifts from "because ops told me to" to "because my deal scores depend on it."
After three weeks of running weekly on one team, deals with populated next-step fields went from 35% to 78%. Not from a mandate. Because the scoring made the gap visible.
Bad data isn't a blocker. It's the first thing the diagnostic surfaces.
Why Marketing Leaders Should Care
If Marketing sources 40% of pipeline but half those deals are zombies or stage-inflated, your MQL-to-revenue attribution is built on sand. Marketing's "contribution" looks strong in the CRM -- but it doesn't convert proportionally because the denominator is inflated.
Real pipeline, after zombie and stage-inflation removal, is the denominator Marketing should use. If real pipeline is 60% of reported, Marketing's true contribution might be higher or lower than dashboards suggest. Either way, the current number is wrong.
Outreach's research on AI-driven forecasting found that companies using structured AI forecasting see 15-20% higher accuracy and 25% shorter sales cycles. Those gains give Marketing a real denominator for attribution -- better resource allocation across the funnel.
Getting Started
You don't need the full ten-dimension system to start. Minimum viable chain:
- Pull open deals from CRM
- Check three zombie signals: no activity in 14+ days, close date pushed 3+ times, single-threaded in a late stage
- Generate a list of deals to disposition this week
Even stripped down, run weekly, this catches the worst pipeline inflation. Teams carry 15-25% phantom pipeline without realizing it -- deals inflating every coverage ratio and forecast number leadership sees.
For the full chain: CRM API access, the ten-dimension scoring framework (the weights above are a working starting point), and a way to render three-layer output. A RevOps engineer or technical operator can stand up the minimum version in a few days.
If you're new to MEDDPICC, start there before building automation on top. The scoring assumes some version of multi-dimensional qualification methodology.
For teams building ICP and qualification frameworks from scratch, I walked through that in How I Built an ICP Scoring Pipeline from Zero -- an upstream skill in the same chain.
Databar.ai documented a similar approach to using coding agents for pipeline inspection. The category is emerging. Operators building these chains now are developing muscle memory that compounds as the tooling matures.
For teams that want this diagnostic without building it, I run consulting engagements that start with exactly this pipeline inspection -- same methodology, applied to your CRM data, three-layer output in the first session.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.