title: "AI Agents for Sales: 3 Failed Architectures" slug: persistent-agents-failed-approaches seo_keyword: "AI agents for sales" meta_description: "AI agents for sales: tried 3 architectures, all failed in production. The stateless iteration pattern that works - tested across 42 PRDs." og_description: "Long sessions forgot their own decisions. Cron jobs had amnesia. Event-driven became its own product. The stateless pattern that actually ships persistent AI agents -- tested across 42 PRDs." cluster: claude-code-operators author: Victor status: published published_date: 2026-03-25 read_time_minutes: 12 description: "AI Agents for Sales: 3 Failed Architectures" domain: steepworks type: article updated: 2026-03-25
Building Persistent Agents That Run While I Sleep: 3 Failed Approaches
I Wanted AI Agents for Sales That Run While I Sleep. Here's What Actually Happened.
I wanted AI agents for sales tasks — enriching 50 target accounts with firmographic data and generating personalized first-touch emails, curating 120+ articles into a weekly newsletter, scoring deal health across a pipeline — running autonomously while I slept. Wake up to finished work, not a crashed process and a $40 API bill.
Everyone is talking about AI agents for sales right now. The market is projected to grow from $7.6B in 2025 to $139B by 2033. The promise is real. The execution gap is brutal.
I tried three architectures. All three failed in production. Not in theory — in practice, running real GTM workflows against real data. This is the buildlog of those failures, and the pattern I eventually found that ships.
These failure modes apply regardless of which LLM you use — Claude, GPT-4, Gemini. Context windows, state management, and infrastructure complexity are architectural problems, not model problems.
I've been building AI-into-GTM systems for 2.5 years. Not evaluating vendors — building the systems. What follows is the engineering notebook of what broke and what I'd tell you before you spend three weeks on an architecture that won't survive its first night run.
Failure 1 — The Long-Running Session That Forgot Its Own Decisions
The task: enriching 50 target accounts with firmographic data, scoring ICP fit, and generating personalized first-touch email drafts. Expected runtime: 2-4 hours of continuous agent work.
After roughly 25-30 tool calls, the agent started losing early context. It re-researched companies it had already scored. It made contradictory ICP assessments of the same account — "strong fit" at step 8, "marginal fit" at step 35 with identical input data. Configuration decisions from the first 10 minutes (target industry, persona parameters, email tone) evaporated.
The insidious part: no error. No crash. The agent kept running with degrading quality. Output looked plausible but was internally inconsistent. I only caught it because a sales rep flagged that two emails to the same company said opposite things about our value proposition.
Even with 200K token context windows, multi-step agents fill that space fast. Each tool call response, each intermediate result, each reasoning step consumes tokens. By step 30, the model operates on a fraction of the original context. It doesn't throw an error — it silently drops older information and keeps generating confident output from an incomplete picture.
The compounding math: 95% per-step accuracy gives you only 60% end-to-end success over a chain of reasonable length. Your agent makes a wrong move 1 in 20 steps, and those errors compound.
Real cost: $15-40 in wasted compute per failed run, corrupted outputs requiring manual redo, and three full runs before I even understood the failure mode. The context failure is invisible. Your agent doesn't stop — it just gets worse.
Long-running sessions are a demo pattern, not a production pattern. They work for 15 minutes. They degrade silently over hours.
Failure 2 — Cron Jobs Without Memory (The Goldfish Agent)
After the long-session failure, the obvious move: break work into smaller chunks on a schedule. The task: daily newsletter intelligence — scanning 120+ GTM articles, scoring relevance, generating a curated digest. Each run should process the day's new content and build on previous selections.
Cron-triggered invocations. Daily at 6am, process the latest batch. Each run short, avoiding context bloat. Problem solved, right?
Each invocation started completely fresh. No memory of what the previous run had done. Monday's run flagged an article about AI SDRs. Tuesday's run flagged the same article because it had no record of Monday's curation. By Friday, the week's digest had duplicates, contradictions, and no coherent editorial thread. The agent wasn't persistent — it was amnesiac on a timer.
Three workarounds, each creating its own problem:
File-based state. Write a JSON state file between runs. Fragile. The file format drifts as you bolt on new fields. Partial writes corrupt state — crash mid-write and your entire history is gone. No schema enforcement means subtle bugs accumulate.
Database state. Store everything in Postgres. Over-engineered for the problem. Now you're maintaining a database schema, writing migrations, building query logic, and managing connections for what should be a simple daily agent. The 88% of AI agents that never make it to production aren't failing because the AI is bad — they're failing because the plumbing becomes its own product.
Prompt stuffing. Pack the previous run's output into the next run's prompt. This brings you back to Failure 1 on a slower timeline. After a week of accumulated context, you're at the context window wall again.
The uncomfortable insight: the state management problem is harder than the AI problem. I was spending 70% of engineering time on plumbing and 30% on agent logic. The ratio was backwards, and the plumbing still wasn't reliable.
Failure 3 — The Event-Driven Architecture That Became Its Own Product
If cron is too dumb, go event-driven. The task: deal intelligence automation. When a deal moves to Stage 3 in the CRM, pull the latest account signals, update the deal health score, and draft a coaching note for the rep.
Webhooks. Deal moves to Stage 3, webhook fires, agent takes action. Smart, targeted, responsive. In theory.
The complexity exploded. Event ordering matters — what happens when the "deal moved" event arrives before the "lead enriched" event? The same webhook fires twice (deduplication needed). The agent fails mid-event (dead letter queue needed). Retry logic — re-process or skip? Every edge case spawned two more.
I spent three weeks building infrastructure. Event queues, deduplication logic, failure recovery, retry policies, monitoring dashboards. The agent itself — the actual AI logic — took two days. I'd built a distributed systems platform to run what amounted to a smart CRM macro.
The irony: the event-driven agent ran reliably. The infrastructure worked. But it did less than a well-prompted script would have done in an afternoon, and it required ongoing maintenance of a system I'd built from scratch.
If your agent infrastructure is more complex than your agent logic, you've built the wrong thing. Those three weeks should have been spent on better prompts, better evaluation criteria, better reasoning chains. That's where differentiation lives.
The Pattern That Actually Works — The Ralph Wiggum Method
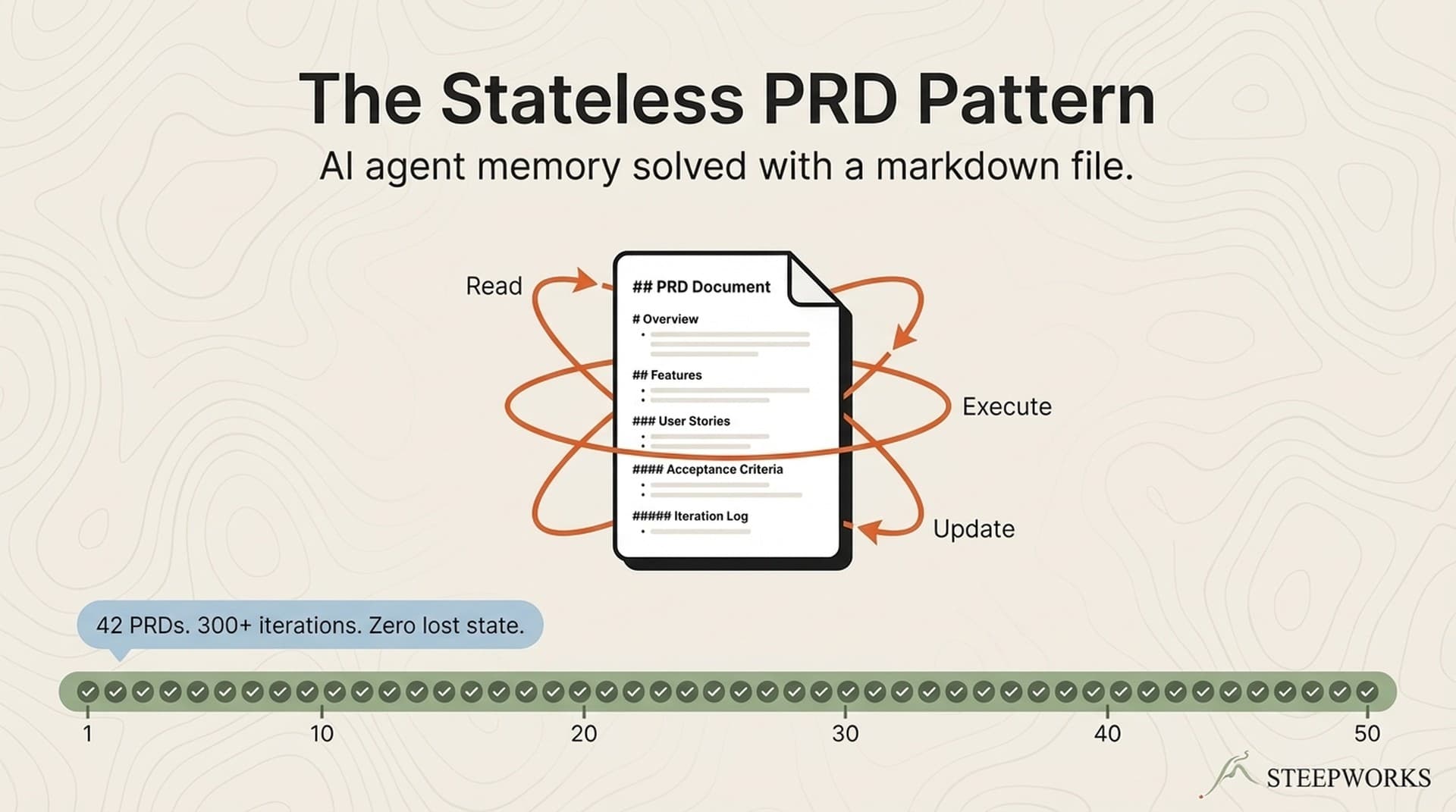
The three failures shared a root cause: I was trying to make the agent persistent. But the agent doesn't need to be persistent. The state needs to be persistent. The agent can be stateless — as long as the file it reads from and writes to never forgets.
This method powers everything from multi-agent newsletter curation to the full AI GTM stack I use daily.
How the Protocol Works
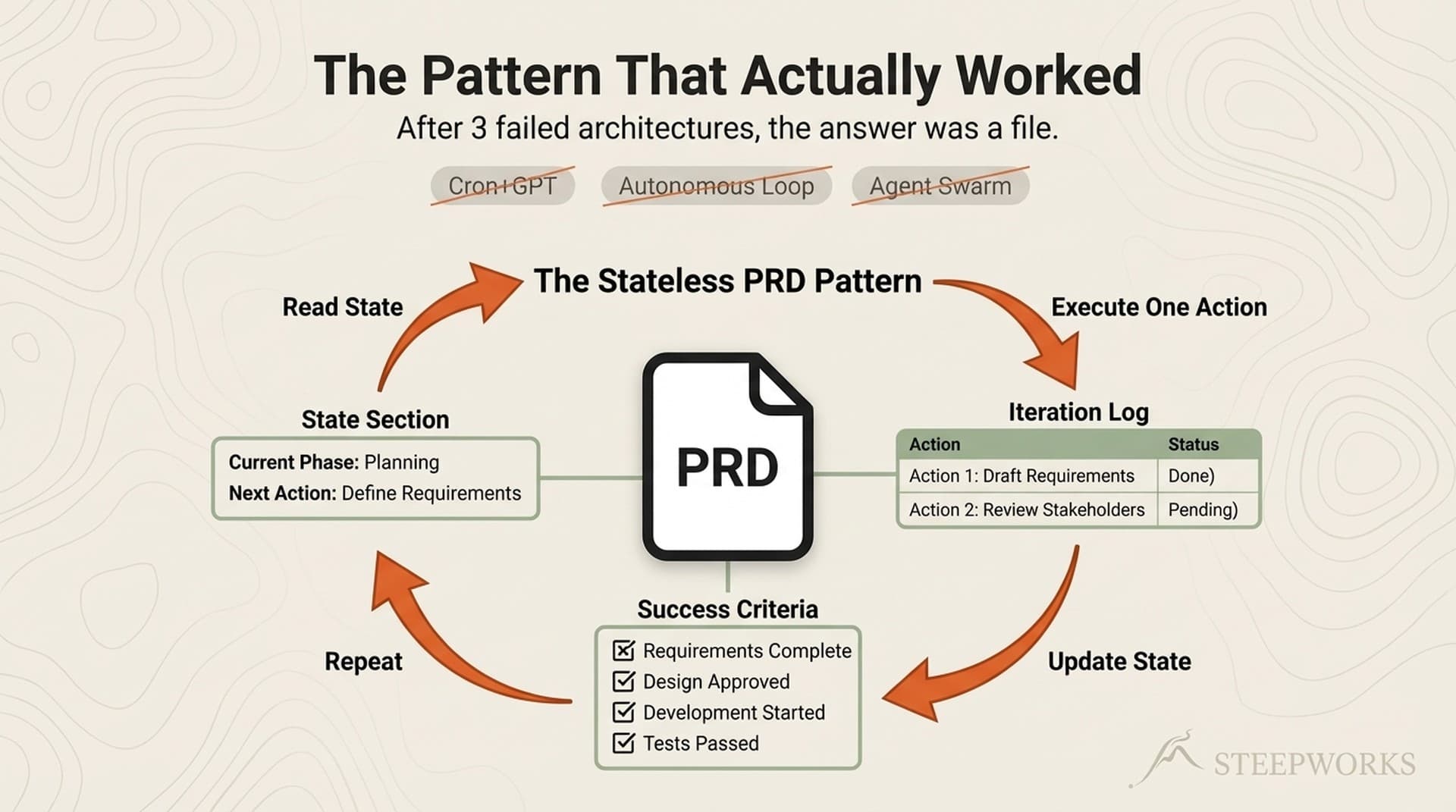
Each invocation follows an 8-step iteration:
-
Read state from the plan file. Parse current phase, iteration count, next action, blockers, and running learnings from prior iterations. The plan file is a structured document — a PRD — containing every piece of state the agent needs.
-
Pre-flight checks. Verify context budget (flag if the phase touches more than 10 files, block at more than 20). Confirm tool availability. Enforce scope boundaries. Check running learnings for applicable patterns. Verify branch continuity.
-
Execute exactly one action. A single file read or write. A single command. A single research query. Not two. One atomic action. (professional Claude Code implementation)
-
Update state in the plan file. Increment iteration count, record what was done, specify what happens next, note blockers. (See also: claude md)
-
Update the iteration log. Append a row with date, phase, action, result, notes. The audit trail.
-
Check success criteria. Two-stage validation: does the output match the phase specification? At phase boundaries, run a quality gate — content review or adversarial critique.
-
Check escape hatches. Same action failed 3 times? Try an alternative. 5 iterations with no progress? Escalate to a human. Total iterations hit max budget? Stop and summarize. (free setup guide)
-
Output exactly one signal.
CONTINUE,TASK_COMPLETE, orBLOCKED_NEED_HUMAN.
Why This Solves the Three Failures
The plan file IS the memory. Updated every iteration, it contains an iteration log recording every action plus running learnings — compressed operational insights accumulated across iterations. Any agent (or human) can pick up where the last one left off by reading the file.
- Context window exhaustion (Failure 1): Each iteration starts fresh. The plan file is the only state to load, designed to stay within budget.
- Amnesiac cron jobs (Failure 2): The file provides persistence without custom state management infrastructure. Just a text file in version control.
- Infrastructure complexity (Failure 3): No event queues, no deduplication logic, no dead letter queues. The plan file handles ordering, idempotency, and failure recovery in plain text.
Two execution modes. Manual iteration: human invokes the skill, reviews output, invokes again. Automated loop: a plugin intercepts the completion signal — if it says CONTINUE, it re-feeds the prompt. True walk-away execution.
What This Looks Like at Scale
Three production PRDs from my active system:
-
A 20-phase PRD for building a persistent agent fleet across content production, audience growth, and revenue operations. Max iterations: 60. The PRD itself is the coordination layer for work that would otherwise require a project manager.
-
A 74-article content production PRD running parallel sub-agents with file-based human review. Quality bar: adversarial. Each article goes through outline, critique, draft, and quality gate — all via the same stateless protocol.
-
An infrastructure cascade PRD codifying a reusable playbook from one city's newsletter SEO setup to the next.
The economics: individual runs cost $0.50-2.00. Failures are isolated — a bad iteration corrupts nothing because previous state is in git. Compare to $15-40 per failed long-running session.
How PRDs Get Scoped — The Deep-Planning Pipeline
Execution quality depends entirely on decomposition quality. A well-scoped PRD executes reliably. A vague task dumped into an agent session produces Failure 1 every time.
The planning pipeline runs 7 phases before work begins:
1. Workstream alignment. Identify which mental mode — consulting, content, infrastructure — and load the right context.
2. Context sufficiency check. Does the request have concrete success criteria, at least one constraint, and clear stakeholders? If two or more are missing, interview the human first.
3. Context gathering and skill audit. Read synthesis documents, search existing patterns. Minimum 3 relevant skills identified and mapped to phases, minimum 2 excluded with reasons.
4. PRD generation. Every complex task gets a structured plan file.
5. Phase sizing discipline. Each phase stress-tested. More than 3,000 lines of source material? Add an extraction sub-phase. More than 10 file operations? Split by entity. Target: 15-25 phases for substantial PRDs.
6. Quality bar classification. Every PRD gets a deliverable type (infrastructure, content, research, analytics) and a quality bar (structural, semantic, adversarial).
7. Historical sizing calibration. An intelligence index with empirical data from 33+ completed PRDs. Infrastructure PRDs average 0.4-0.56 iterations per phase. Sizing formula: Max Iterations = (Phases x 2) + (Success Criteria / 3) + 5, plus a 15% uncertainty buffer. Calibrated from production data, not guesswork.
The pipeline enforces context mode per phase: direct for under 3,000 lines, extract_then_assemble for 3,000-6,000 lines (96% context reduction), map_reduce for over 6,000 lines. This solves Failure 1 at the planning stage — the context window problem is engineered around before execution begins.
One detail worth mentioning: every skill listed in the audit gets cross-checked against phase actions. If a review skill is mapped to Phase 4 but Phase 4 doesn't invoke it, the phase gets rewritten. This prevents "skill drift" — phases defaulting to generic task language instead of calling mapped skills. Drift is most common in later phases, where planning fatigue sets in.
Multi-Model Debate — Why a Second Opinion Catches What You Miss
A single model planning and reviewing its own work has the same blindspots in both passes. Same principle as code review — the value isn't expertise, it's fresh eyes.
I use a cross-model adversarial review that invokes a separate model in read-only mode to critique plans before execution. It reads the target file, auto-detects document type, selects the appropriate review prompt, and outputs numbered issues with severity, locations, and suggested fixes. Verdict: APPROVED or REVISE. Maximum 3 rounds — diminishing returns after that.
For any PRD with 10+ phases, this review is automatic. The cost of a bad plan at 20 phases is too high to skip a fifty-cent review.
A real example: my DMVFamilies SEO cascade PRD ran through cross-model review before execution. The review found 9 issues — phase sizing problems and missing verification methods — addressed before a single iteration ran. Without it, those structural problems would have surfaced as confusing failures 30 iterations deep.
Why multi-model specifically? A different model trained on different data with different reasoning patterns catches categories of problems the planning model cannot see. I've watched it catch scope creep the planner introduced while optimizing for completeness. I've seen it flag missing success criteria the planner assumed were implied. The $0.50 cost-per-review has saved multiple full PRD rewrites.
Three Rules for Persistent Agents (And One Note on Teams)
After building, breaking, and rebuilding these systems:
1. Make the agent stateless, make the state persistent. Don't keep an agent alive for hours. Let it read state, act, write state, exit. The plan file IS the memory, and each iteration is independent.
2. Buy the plumbing, build the intelligence. Scheduling, webhooks, retry logic, authentication — solved problems. Use Pipedream, Temporal, or n8n. Spend engineering time on prompts, evaluation criteria, reasoning chains. That's where differentiation lives.
3. Design for failure isolation. Every run independent. A bad run corrupts nothing. A good run advances state. Escape hatches — 3 failed attempts triggers an alternative approach, 5 iterations without progress escalates to a human — make failure a system event, not a crisis.
And one overarching discipline: scope your work before your agent touches it. The planning pipeline is where the real work is. A well-scoped PRD with 15-25 phases and calibrated escape hatches executes reliably. A vague task dumped into an agent session produces Failure 1 every time. The planning is not overhead. The planning is the product.
A note on teams. This scales beyond solo operators. Each team member runs stateless iterations against the same state file. The file prevents conflicts. The human review step prevents quality drift. I've seen a 3-person ops team adopt this in a week, with the state file as their shared source of truth. Onboarding is reading the file. Debugging is reading the log. Handoffs are free.
The build-time comparison: long-running sessions took a day to set up and failed immediately. The cron approach took a week and produced inconsistent results. Event-driven took three weeks and worked but was over-engineered. The stateless iteration method took two days and has been in production for months. Simpler systems ship faster and break less.
Here's the honest take: I've got agents that run while I sleep. They're not elegant. They're stateless functions that read a file, do one thing, and write the result back. They've been running in production for months — plans scoped by one model, reviewed by another, run by a third. The persistence isn't in the process. It's in the artifact.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.