title: "Agentic Workflows: Hybrid Over Fully Autonomous" slug: hybrid-pipedream-claude seo_keyword: "agentic workflows" meta_description: "Agentic workflows: fully autonomous costs /mo. Hybrid with Pipedream: /mo for 313 sources. Every component and 5 production failures documented." og_description: "Built a fully agentic event pipeline. It burned $47/week. Tore it down and built a hybrid: Pipedream for orchestration, Claude for classification, Cloudflare for export. 313 sources at $8/month." cluster: claude-code-operators author: Victor status: published published_date: 2026-03-25 read_time_minutes: 11 description: "Agentic Workflows: Hybrid Over Fully Autonomous" domain: steepworks type: article updated: 2026-03-25
How a Hybrid Pipedream + Claude Architecture Handles 313 Event Sources
I Built a Fully Agentic Event Pipeline. Then I Tore It Down.
The first version was pure AI. Claude handled everything — deciding when to scrape, which sources to check, how to classify events, when to retry failures. Elegant, intelligent, and burning $47 in API costs in a single week processing events that a cron job could have fetched for free.
Every article about agentic workflows tells you AI agents should reason, plan, and act autonomously. Nobody tells you what happens when that agent re-classifies 2,000 events because it "wasn't confident enough" in its previous classifications. Or retries a failed scrape 40 times because the retry logic is also agentic. The agent wasn't broken. It was doing exactly what I asked — reasoning about every decision. The problem: most of those decisions didn't need reasoning.
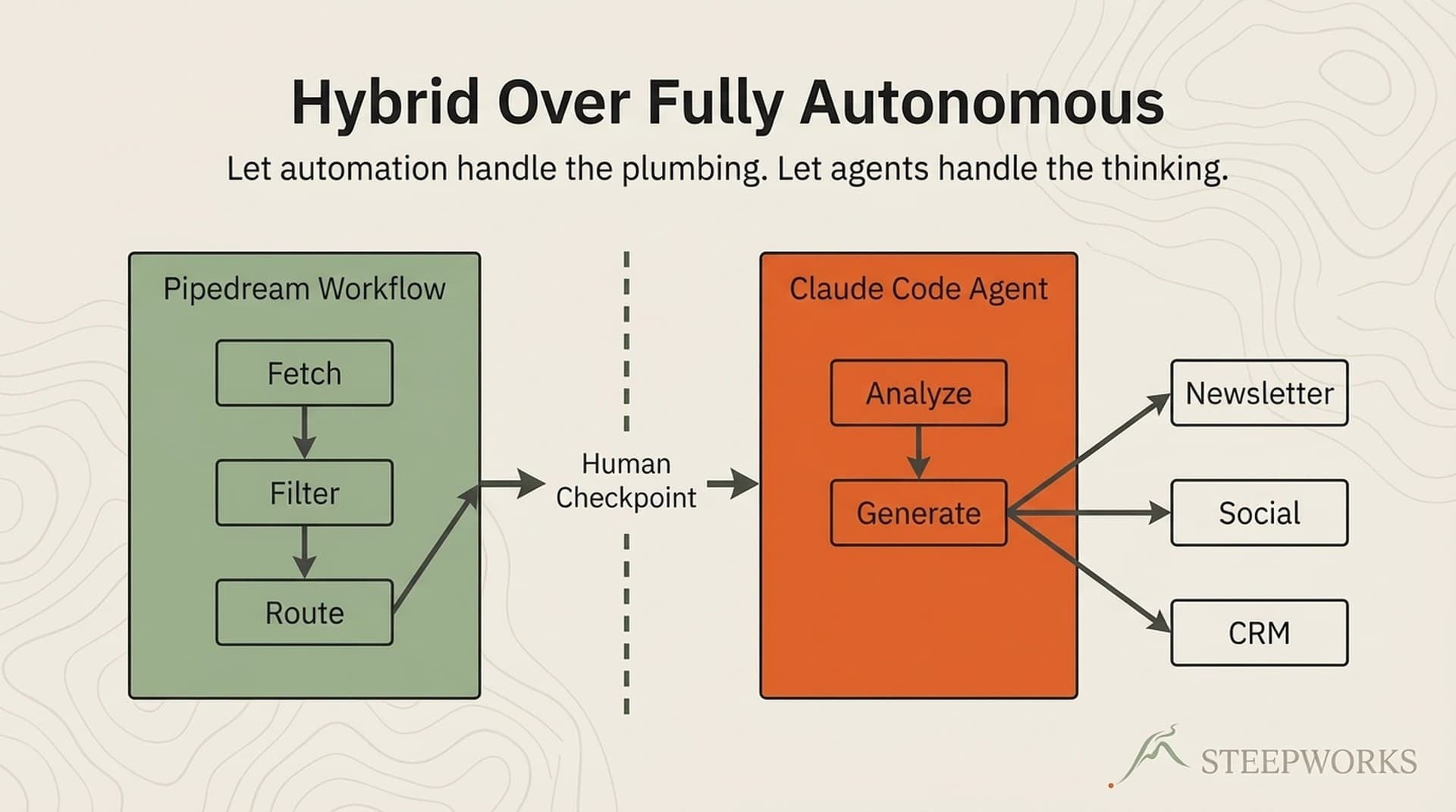
This is a buildlog of a hybrid architecture processing 313 event sources for two family events newsletters. Pipedream handles orchestration — scheduling, HTTP, data flow, error handling. Claude handles intelligence — classification, content generation, quality checks. A Cloudflare Worker handles export — querying Supabase, computing date-separated urgency buckets, pushing newsletter-ready markdown to GitHub. The system runs at ~$8/month instead of $200. Every component, every tradeoff, and why the most reliable production pipelines aren't fully agentic.
If you don't run a newsletter pipeline, swap "event sources" for "lead sources," "classification" for "lead scoring," and "newsletter export" for "CRM enrichment." The architecture is identical. Every pipeline has mechanical tasks and judgment calls — and the expensive mistake is letting AI handle both.
The System at a Glance — 313 Sources, 5 Phases, 2 Newsletters
Sources — 313 venues, aggregators, and community boards across two metro areas — feed into scrapers powered by Firecrawl's headless browser, RSS feeds, and direct APIs. Pipedream orchestrates scheduling, routing, and error handling. When data needs intelligence — deciding whether an event is family-friendly, estimating age range, scoring relevance — Claude steps in. Everything lands in Supabase. A Cloudflare Worker handles export: querying Supabase, recomputing urgency from actual dates, building newsletter-ready markdown and JSON, pushing to GitHub via the Contents API.
Five phases, each a dedicated module: fetch (Inoreader RSS, venue scrapers, APIs), classify (Claude Haiku dual-audience prompt), store (Supabase upsert with fingerprint dedup), export (date-bucketed markdown and JSON), notify (Slack summary with run metrics).
Two newsletters consume this pipeline: Baltimore family events and DC/DMV family events. Same infrastructure, different geographic filters and brand voices. A region column partitions data at the storage layer, with region-scoped views enforcing the boundary. One pipeline, two outputs, no duplication.
The 313 sources break down: 200+ venue scrapers (museums, zoos, libraries, rec centers), 24 Macaroni Kid community editions, 17 program sources (swim, STEM, art classes), seasonal sources, and social monitors. Scheduling is tiered: P0 sources scrape daily, P1 Monday and Thursday, P2 weekly.
Most newsletter operators curate 10-20 sources manually. The gap between manual curation and comprehensive coverage is where the architecture decisions live. For a marketing team, this is the gap between your SDR manually checking 20 intent signals and a pipeline monitoring 300+ data points across Bombora, G2, LinkedIn, and product analytics.
For the evaluation layer on top: How 7 AI Agents Evaluate 120 Articles Weekly.
What Pipedream Does (and Why an AI Agent Shouldn't)
I use Pipedream because it's developer-friendly with a generous free tier. But the pattern works with any orchestration platform — Zapier, Make, n8n, even cron jobs and a shell script. The point isn't the tool. It's the principle: keep orchestration deterministic, inject AI only at judgment nodes.
Scheduling. Cron-triggered workflows. P0 venues scrape daily at 6 AM. P1 Monday and Thursday. P2 weekly. This is a solved problem. An AI agent that "decides" when to scrape adds latency, cost, and a new failure mode for zero benefit. The schedule hasn't changed in months.
HTTP orchestration. Each scrape is an HTTP request to Firecrawl's headless browser API. Pipedream manages the request chain: trigger, fetch, transform, route. Deterministic. Retryable. Debuggable. When a venue changes their DOM, I see exactly which step failed. No ambiguity, no "the agent tried something creative."
Error handling. Built-in retry logic — timeouts, rate limits, 502s. Three retries with exponential backoff. If a venue fails three consecutive times, it flags to Slack. An agentic error handler that "reasons about" failures sounds appealing until you realize the correct action for a 502 is always "wait and retry."
Data routing. Baltimore events route to one schema. DMV events route to another. Conditional logic, not intelligence.
The Pipedream-to-Worker handoff. Pipedream's last job is triggering the Cloudflare Worker. After scraping and classification, Pipedream fires an authenticated POST to the Worker's /run-all endpoint. The Worker takes over. This clean boundary means either side changes independently. I've rewritten the Worker three times without touching a single Pipedream workflow.
The orchestration layer runs at zero dollars. The moment you make any of these components agentic, you're paying per-token for decisions that should be if/else statements.
What Claude Does (and Why Pipedream Can't)
An event listing says "Saturday Morning Art Studio — All Ages Welcome." Is this a toddler finger-painting class or an adult watercolor workshop? The venue is a community center that hosts both. The price ($15) doesn't disambiguate. The time (10 AM Saturday) fits either audience. No regex, no keyword matching, no rules engine handles this reliably across 313 sources with different formatting conventions.
If you run lead scoring, you've hit the same wall. A VP at a 50-person company who visited your pricing page twice is not the same signal as a VP at a 5,000-person company doing the same thing. The title matches, the behavior matches, but the context requires judgment.
Each event gets scored for two audiences simultaneously — families with kids 0-14, and general adults. The classifier outputs: family-friendly score (1-10), age range, content pillar, general relevance score, audience category, and vibe. A single event can be high-family, low-general (kids' storytime) or low-family, high-general (brewery tour that offers babysitting).
Why Haiku, not a larger model. Classification is high-volume, moderate-complexity. Claude Haiku at $1/$5 per million tokens handles this accurately. Roughly $0.01 per event. At 500+ events per week, about $5/week. I reserve larger models for tasks that need deep reasoning — classification isn't one of them.
The classifier prompt is the contract. It defines geographic scope, scoring rubrics, audience definitions, output schema. When classification quality drifts, I update the prompt — not the code.
The Cloudflare Worker — Why a Stateless Edge Function Handles the Export
Pipedream is great at triggering things. Not great at complex data transformation with date math, urgency bucketing, and multi-format output. The export needs to query Supabase for approved events, recompute urgency from actual dates (stored urgency goes stale overnight), group events into this_weekend / next_week / coming_soon / ongoing buckets, render JSON and markdown, and push to GitHub. Too much logic for a workflow step. A proper application — that runs for about three seconds.
Date-separated urgency. The Worker's computeUrgency() function is the key piece. An event classified as "next_week" on Monday is "this_weekend" by Thursday. The Worker recalculates at export time using actual date boundaries. Multi-day events spanning boundaries get handled correctly. Events with end dates in the past expire. Deterministic date math, not AI — but critical to newsletter quality.
The export output. Two formats: machine-readable JSON with full metadata and human-readable markdown grouped by urgency tier. Both pushed via GitHub Contents API as timestamped files that become input to the newsletter generation skill.
Why Cloudflare Workers. Edge execution, scale to zero, free tier, native bindings to D1 for logs, KV for OAuth tokens, and cron triggers. No server, no cold starts that matter, no always-on billing.
The pipeline orchestrator. The Worker chains five phases sequentially. Each returns a standardized result with success/failure, timing, item counts, error arrays. If fetch returns zero items, it skips classify and store but still runs export — export queries the database independently and may have events from local scrapers that bypassed the Worker.
For a marketing team, the equivalent is a serverless enrichment function after your CRM sync — too complex for a Zapier step but doesn't justify a dedicated server.
Supabase as the Central Nervous System
Most event pipelines are stateless — scrape, classify, publish, discard. This one stores everything, permanently. That turned out to be the single most valuable architectural choice.
The events table isn't a staging area — it's the analytical backbone. Over 50 columns from source identification through AI classification to newsletter tracking. The schema enforces constraints at the database level — valid enums for urgency, content pillar, age range, cost type, moderation status — so classification errors get caught on insert, not in the newsletter.
Cross-source deduplication. When the same "Aquarium Dolphin Show" appears from both RSS and a venue scraper, a BEFORE INSERT trigger generates an MD5 fingerprint from normalized title, venue, and date, checks for matches, and merges (if higher priority source) or skips. Source priority: P0 at 100, P1 at 90, manual entries at 80, official RSS at 70, aggregators at 50, social at 30. A later migration added fuzzy dedup using pg_trgm — with a kill switch, because fuzzy matching merges two different events at the same venue more often than you'd like. (See also: daily cos brief)
Temporal accumulation is the real asset. After 3+ months of operation, patterns emerge you can't see in a single run. Source reliability becomes measurable. Seasonal patterns surface — outdoor events spike in May, enrollment opens in August and January. Classification quality is auditable month-over-month. The classified dataset doubles as training data: after six months, 10,000+ labeled examples for fine-tuning or building a rule-based pre-filter that catches the easy 60% before Claude sees them. (See also: agents)
For a marketing team: the difference between a lead scoring system that forgets its inputs and one that stores every scored lead with raw signals and outcomes. After six months, the stored version tells you which signals predict conversion. The stateless version can't. (professional Claude Code implementation)
The Boundary Line — Deterministic vs. Intelligent
If the correct action is always the same given the same input, it's deterministic. If it depends on context, nuance, or implicit signals, it needs intelligence. (See also: claude md)
Four questions before making any component agentic: (free setup guide)
- Would a human make the same decision every time? If yes, automate deterministically.
- Does the decision require reading unstructured text? If yes, you need AI.
- What's the cost of a wrong decision? Low-cost errors: deterministic. High-cost errors: AI with human review.
- What's the token cost at volume? If it exceeds $0.10/decision at 1,000+/day, find a deterministic approximation or smaller model.
| Component | Type | Why | Marketing Equivalent |
|---|---|---|---|
| Scrape scheduling | Deterministic | Same schedule every time | CRM sync cadence |
| HTTP retry logic | Deterministic | Always "wait and retry" | API call retry |
| Event deduplication | Deterministic | Fingerprint + source priority | Lead dedup |
| Date urgency | Deterministic | Pure date math | Deal stage aging |
| Audience classification | Intelligent | Context and nuance | Lead scoring |
| Age range estimation | Intelligent | Implicit signals | Buyer stage detection |
| Data routing | Deterministic | Region column | Territory assignment |
| Quality gate | Intelligent | Pattern recognition | Scoring anomaly detection |
| Export format | Deterministic | Template rendering | Email template rendering |
Map the decisions, draw the boundary, resist the temptation to let AI handle mechanical tasks just because it can.
For the broader systems principle: Systems Over Tactics: Why Most AI Implementations Fail at Month 3.
What Broke — Five Production Failures
Failure 1: The $47 week. The fully agentic version re-classified 2,000 events because confidence was "too low" — with no hard threshold. I replaced it with a deterministic rule: above 0.7 means done, below 0.7 means flag for human review. Cost dropped from $47/week to under $8/month.
Failure 2: The retry spiral. An agentic retry handler "reasoned" that a 503 meant the page structure had changed and tried alternative scraping strategies. Forty API calls later, the venue was just temporarily down. Simple exponential backoff with a three-attempt limit would have cost nothing.
Failure 3: Classification drift. After three weeks, the classifier scored everything above 7. The prompt had no calibration anchors — no examples of what a "4" versus an "8" looks like. Fix: five calibration examples. A 4 is "adult-focused event at a family venue." An 8 is "explicitly designed for the target age range with programming details." If you run any AI scoring system, calibration examples are the single most important prompt investment.
Failure 4: The dedup trap. I initially used Claude for duplicate detection. It worked — at $0.50/day for a task fuzzy string matching handles at zero cost. I switched to deterministic dedup (MD5 fingerprint plus source priority) and added fuzzy dedup as a second stage with a kill switch.
Failure 5: The stale urgency bug. A PostgREST filter using neq.expired silently excluded events with NULL urgency — SQL evaluates NULL != 'expired' as NULL (falsy), so 63+ future events vanished. Fix: use an or() filter, and move urgency computation out of the database. The Worker now recomputes from actual dates at export time.
Every failure came from the same root cause: putting intelligence where determinism belonged, or trusting stored state where computed state was needed. For a taxonomy of agent design patterns, Microsoft's reference architecture is worth the read.
The Numbers
Monthly cost for the hybrid architecture:
- Pipedream orchestration: $0 (free tier)
- Firecrawl scraping: ~$2/month (313 sources, tiered schedule)
- Claude classification (Haiku): ~$5/month (500+ events/week)
- Supabase storage: $0 (free tier, 25 migrations deep)
- Cloudflare Worker: $0 (free tier)
- Total: ~$7-8/month for 313 sources, 2 newsletters, ~2,000 events/month
The pure agentic version: $150-200/month. A 25x multiplier. At enterprise lead-scoring volume, that pattern saves $20K-50K/year.
Reliability. Daily operation since January 2026. Two outages: one API provider issue resolved by retry, one database migration resolved in 20 minutes. Zero AI-caused outages since going hybrid. The fully agentic version had three AI-caused outages in its first week.
Overhead. About 30 minutes per week. Venue changes its website, scraper fails, Slack alerts, I update the config.
The production test: Can it run 30 days without human intervention beyond scheduled maintenance? The hybrid passes. The pure agentic version never made it past five days. For framing on what "agentic AI" means, MIT Sloan's explainer is a solid starting point.
Should You Build This?
Not every pipeline needs this architecture.
When pure automation is enough. Fewer than 50 sources, well-structured data, classification expressible as if/else. Most newsletter curation and simple lead routing falls here.
When you need hybrid. Your pipeline crosses the "judgment threshold" — decisions requiring understanding of unstructured text, context, or nuance. But those decisions are bounded and high-volume. Most production systems that need AI end up here.
When full agentic makes sense. Low-volume, high-complexity, cost per decision justifiable. A deal-review agent evaluating five deals per day can afford $2/evaluation. A classification pipeline processing 500 events per day cannot.
The architect's checklist:
- List every decision point in your pipeline.
- For each: is the correct action always the same? If yes, deterministic.
- For AI decisions: what's the per-decision token cost at your volume?
- Can you use small models for bounded tasks, reserving larger models for reasoning?
- What's your acceptable monthly AI spend? Work backward.
Store the inputs and outputs. After six months, you'll have training data, a quality audit trail, and drift detection. The pipeline that forgets its work can never improve.
What I'd build differently: Start deterministic. Add AI at the first decision point where rules fail. Measure cost. Only expand AI when the quality gap justifies the spend. The temptation is to start agentic and rein it in — the economics run the other direction.
For how this pipeline fits into a broader stack: The AI GTM Stack I Actually Use: 14 Tools, 3 Integrations, 1 Architecture.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.