title: "Knowledge Graph: 889 Docs, 52 Skills, No Database" slug: knowledge-graph-52-skills seo_keyword: "knowledge graph" meta_description: "An AI agent hallucinated a file path and built an entire analysis on nothing. I built a knowledge graph -- 3 YAML configs, 4 scripts, 2 git hooks." og_description: "An agent referenced a file that didn't exist and built a confident analysis on top of it. I built a flat-file knowledge graph with schema validation, pre-commit hooks, and health scoring to prevent it. No database required." cluster: knowledge-systems author: Victor status: published published_date: 2026-03-25 read_time_minutes: 7 description: "Knowledge Graph: 889 Docs, 52 Skills, No Database" domain: steepworks type: article updated: 2026-03-25
The Knowledge Graph That Powers 52 Skills: Schema, Validation, Zero Hallucinations
Three months ago, an AI agent in my system referenced a consulting framework called competitive_positioning_matrix.md. Confident file path. Plausible name. The agent built an entire analysis on top of it -- strategic recommendations, competitive positioning, the works. The output almost shipped.
The file didn't exist.
The agent hallucinated a reference that sounded like something I'd write, in a directory where I'd reasonably store it, and produced output grounded in nothing. That failure doesn't look like failure -- it looks like competent work product until you check the source.
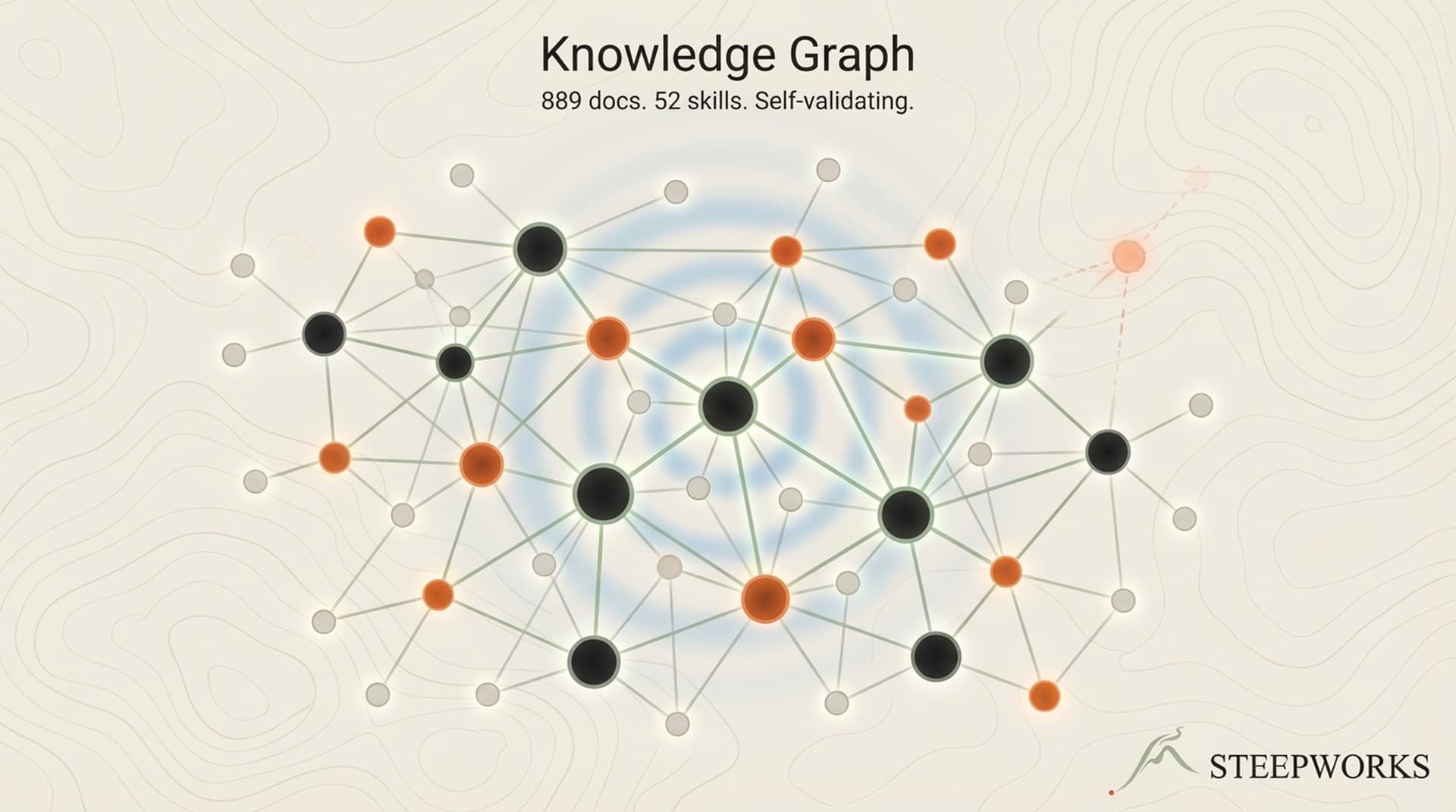
I built a knowledge graph to fix this by making invalid references structurally impossible. 889 documents, 52 AI skills. No database. No SPARQL. Three YAML config files, four Python scripts, two git hooks. The graph prevents hallucinations by enforcing the reality the agent is allowed to reference.
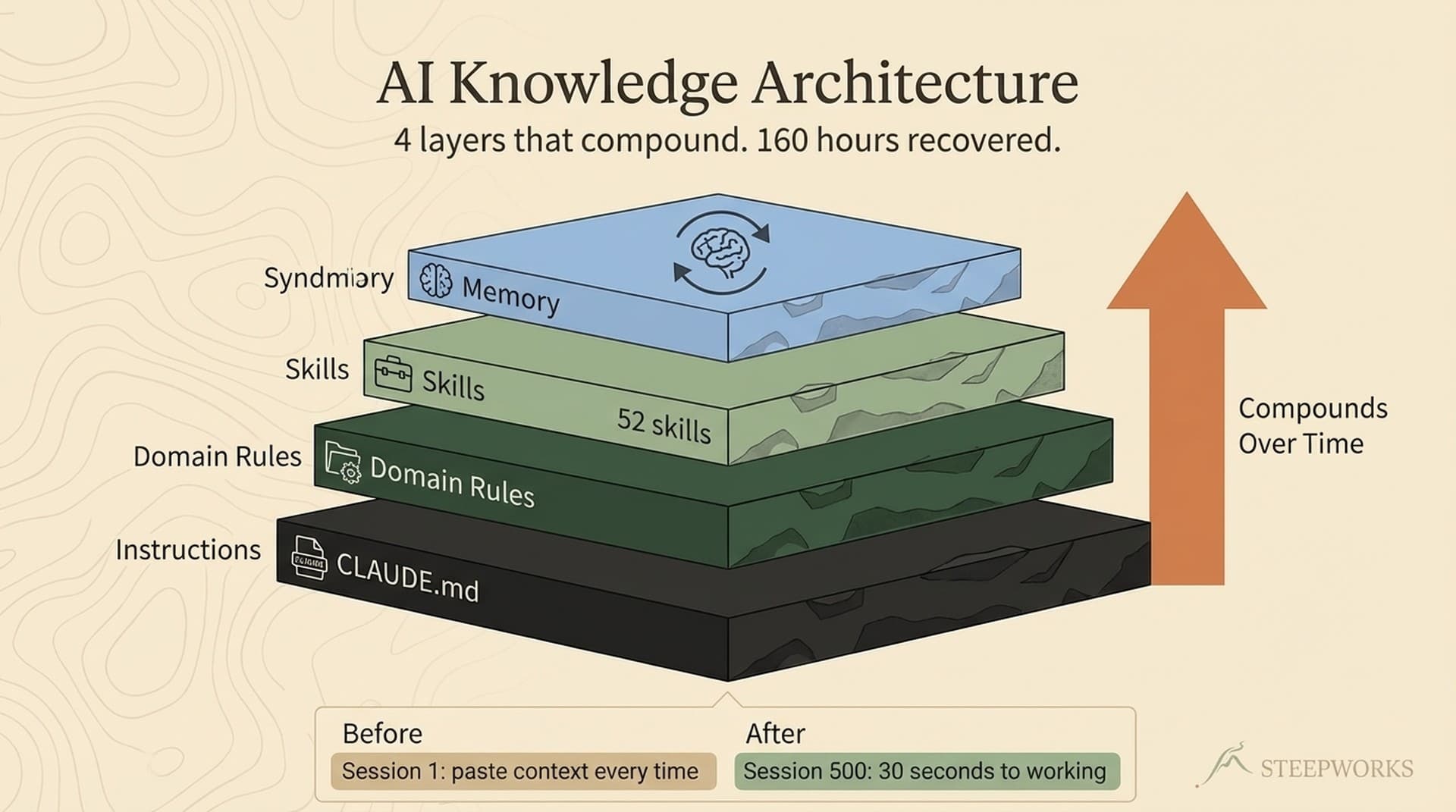
I wrote about the overall architecture -- 17 numbered folders, READMEs as navigation hubs, a memory layer. This article goes deep on one layer: the knowledge graph that makes the whole thing trustworthy.
What Makes a Knowledge Graph Different From Organized Files
Most people stop at organized files. Naming conventions. Folder structure. Maybe tags. It works until AI agents start consuming the content.
Organized files don't do four things that matter:
- Block commits when metadata is invalid. A file with
domain: marketingenters an organized system without resistance. In a knowledge graph, it doesn't --marketingisn't a valid domain. - Auto-generate a queryable index. Organized files require grep. A knowledge graph generates a structured index -- every file, its metadata, its relationships -- rebuilt on every commit.
- Score health across four dimensions. Organized files have no self-awareness. A knowledge graph knows that 85% of its documents have valid frontmatter and 0.7% are stale.
- Track inter-document relationships automatically. Organized files sit next to each other. A knowledge graph tracks what references what.
Folders are passive. A knowledge graph is active -- it validates, indexes, reports, blocks.
The entire infrastructure: 3 config files (schema.yaml, domains.yaml, validation_rules.yaml), 4 Python scripts (validate.py, build_index.py, health_check.py, migrate.py), 2 git hooks. Total cost: zero. Total dependencies: Python and PyYAML.
Projects like Archgate CLI are emerging to enforce architecture decisions via pre-commit hooks -- the same pattern applied to code. The fact that enforcement-at-commit is becoming a category tells you where the industry is headed.
The Schema -- Four Required Fields
Early versions had 12+ fields. Most went unused. Others were inconsistent -- workstream: consulting in one file, workstream: professional in another, both meaning the same thing.
The v4 migration stripped it to four required fields:
# schema.yaml (v4.0)
required_fields:
- description # What this document is
- domain # Which knowledge area (must match domains.yaml)
- type # synthesis | reference | detail | workflow
- updated # YYYY-MM-DD
validation:
missing_required: error # Block commit
invalid_domain: error # Block commit
invalid_type: error # Block commit
invalid_date_format: error # Block commit
missing_tags: warning # Allow commit, warn
Description tells agents what a document is about without reading it. Domain places it in the taxonomy -- one of 16 valid values. Type classifies its role. Updated tracks freshness.
The type taxonomy maps to how agents consume information:
- Synthesis -- hub documents that summarize a domain. Read first. 80% of context in 20% of reading time.
- Reference -- stable frameworks and guides. The authoritative layer.
- Detail -- specific implementations. Load on demand.
- Workflow -- process documents agents follow.
A real frontmatter block:
---
description: "Customer call synthesis framework for MEDDPICC qualification"
domain: professional
type: reference
updated: 2026-02-15
tags: [consulting, meddpicc, customer-calls]
---
Three optional fields: tags (kebab-case, max 7), status (draft/active/archived), related_docs. But the four required fields are load-bearing. Start with minimum viable schema. You can always add fields. You can never undo inconsistency across 800 documents.
16 Domains -- How the Taxonomy Maps Reality
Each domain maps to a top-level folder with its own validation rigor:
# domains.yaml (excerpt)
domains:
finance:
description: "Financial documentation, portfolio intelligence"
folder: "03_finance"
validation_rigor: highest
professional:
description: "Business work: consulting, principles, management"
folder: "01_professional"
validation_rigor: high
prototype:
description: "Prototyping and experimental work"
folder: "12_prototype"
validation_rigor: low
Finance gets strictest validation because wrong numbers have real consequences. Prototypes get relaxed validation because speed matters more than polish. The rigor follows the stakes.
Enforcement path: agent writes a file, stages it, pre-commit hook fires. validate.py checks the domain field against domains.yaml. If the agent writes domain: consulting -- plausible but invalid (correct value is professional) -- the commit is blocked.
The agent can't invent categories. It works within the taxonomy or it doesn't commit. (Knowledge OS guide)
The Pre-Commit Hook -- Where the Graph Gets Teeth
Everything else is configuration until the hook makes it real. (See also: knowledge graph agent)
#!/bin/bash
set -e
REPO_ROOT=$(git rev-parse --show-toplevel) ([Claude for operators](/claude-for-operators))
VALIDATE_SCRIPT="$REPO_ROOT/.knowledge-graph/scripts/validate.py" (See also: [compound knowledge](/claude-code-for-gtm))
STAGED_FILES=$(git diff --cached --name-only --diff-filter=ACM \
| grep '\.md$' || true)
if [ -z "$STAGED_FILES" ]; then exit 0; fi
echo "[knowledge-graph] Validating staged markdown files..."
if python "$VALIDATE_SCRIPT" --staged; then
echo "[knowledge-graph] Validation passed"
else
echo "[knowledge-graph] Validation failed!"
echo "Fix the errors above, then stage and commit again."
exit 1
fi
What validate.py checks:
- Does the file have frontmatter?
- Is the YAML syntactically valid?
- Are all 4 required fields present?
- Is the domain in
domains.yaml? - Is the type one of the 4 valid values?
- Is the date YYYY-MM-DD?
- Are tags under the max count (7)?
Checks 1-6 block the commit. Check 7 warns. Missing metadata is structural; excess tags is cosmetic.
Relaxed path: files in 09_temp/, 12_prototype/, and 05_shop/ get warnings instead of errors. Validation shouldn't slow experimental work, but awareness should remain.
Real story: the first time the hook caught a real error, an agent generated domain: consulting. Without the hook, that file enters the index with a domain matching no folder -- invisible to domain queries. The hook caught it. The agent fixed it. Clean commit on the second attempt.
That's a YAML validation pattern applied to knowledge management. Validation without enforcement is documentation. Enforcement without escape hatches is a prison. Build both.
The Index -- 889 Documents Queryable Without a Database
Post-commit hook runs build_index.py silently. Scans all markdown, extracts frontmatter and wiki-links, generates a single index.json:
documents-- every file with frontmatter and linksby_domain-- 16 bucketsby_type-- 4 bucketsby_tag-- 523 unique tagslink_graph-- outbound wiki-links per documentreverse_links-- inbound links per document
When an agent needs consulting frameworks, it reads index.json, filters by_domain["professional"], then by type: reference. Two lookups, sub-second. Research confirms structured knowledge like this reduces hallucinations by constraining references to what actually exists.
Scale check: 889 documents, 523 tags, 556 wiki-links. The index.json is ~900KB, rebuilds in under 5 seconds. At this scale, a database would be overhead.
You don't need a graph database. You need a graph structure.
Health Scoring -- Where the System Is Honest
Four metrics, each weighted:
Frontmatter Coverage (35%): 85% -- Good. 133 documents still invisible. Mostly workspace drafts and legacy content predating v4. Every new file gets valid frontmatter via the hook. The 15% gap is legacy debt, not drift.
Link Health (25%): 18.3% -- Critical. But many "broken" links are template placeholders like [[RELATED_DOC_1]]. They're intentional blanks, not actual breaks. The metric catches real problems but also flags placeholders. I need to distinguish the two.
Orphan Rate (20%): 87.6% -- Critical. This reflects design reality: README navigation dominates. Wiki-links are sparse. Whether orphan rate is the right metric for a README-navigated system is an open question.
Staleness Rate (20%): 0.7% -- Excellent. Only 6 of 889 documents are stale.
Overall: 56/100. Needs Attention.
I'm showing you that number. Data quality is the real hallucination prevention layer, not model tuning. A knowledge graph that only reports green is a vanity dashboard. This one shows where it's weak.
How This Prevents Hallucinations
Let me be precise. "Zero hallucinations" means: agents cannot commit files with invalid metadata, cannot reference nonexistent domains, and the index reflects only validated documents. It does NOT mean the LLM never generates flawed reasoning. That's a model problem. This is a data problem.
The mechanism is structural. RAG reduces hallucinations by providing context. Prompt engineering constrains output. A knowledge graph with validation constrains the reality the agent operates within.
Recent research shows hallucinations increase with tool count. At 52 skills, the risk surface is significant. The knowledge graph doesn't reduce the model's propensity to hallucinate. It reduces the damage by catching invalid references before they ship.
You can't stop a model from hallucinating. You can stop hallucinations from shipping.
The architecture article covers the broader compounding loop. The knowledge graph is the foundation that makes all of it trustworthy.
Start with 3 Files
You don't need 889 documents. The infrastructure is the same at 50 files as at 900.
schema.yaml -- 4 required fields, valid types. ~15 lines.
domains.yaml -- 3-5 knowledge domains with rigor levels. ~20 lines.
validation_rules.yaml -- exclude paths, relaxed paths. ~25 lines.
Total: 3 files, 60 lines of YAML.
Add the pre-commit hook. Run validate.py --all for your baseline. Fix errors. You have a knowledge graph.
Portability: copy .knowledge-graph/ into any git repo. Run install.sh. Edit domains.yaml. Done. No dependencies beyond Python and PyYAML.
What to defer: wiki-links and link health are valuable past 100+ documents. At 50, focus on frontmatter coverage and valid domains.
Where this scales: teams sharing a repo with AI agents. Multiple AI tools consuming the same knowledge base. Any system where "what files exist" needs to be machine-verifiable. I run three agents against this repo -- all benefit from the same validated index.
The CLAUDE.md setup guide covers the instruction layer on top of the graph. The knowledge graph provides the trustworthy foundation. The instruction file provides behavior. Together, they turn a folder of files into a system an agent can navigate without guessing.
A knowledge graph doesn't have to be a database, expensive, or complex. Three configs, four scripts, two hooks. The real value isn't the technology -- it's the discipline. Schema validation forces you to describe every document. Domain enforcement forces a coherent taxonomy. Health scoring forces you to confront weakness.
The 56/100 health score doesn't bother me. It means the system is honest. And an honest system is one I can trust to ground 52 skills in reality.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.