title: "AI Agent Memory Solved: The Stateless PRD Pattern" slug: ralph-pattern-stateless-agents seo_keyword: "AI agent memory" meta_description: "42 PRDs, 300+ iterations, zero lost state. A markdown file replaces AI agent memory. No database, no framework. Works past step 35 where stateful agents fail." og_description: "AI agents degrade after 35 steps -- 2% quality loss per step compounds to under 50% accuracy. The Ralph Pattern uses a markdown PRD as memory: read state, one action, update, exit. 42 PRDs. Zero loss." cluster: claude-code-operators author: Victor status: published published_date: 2026-03-25 read_time_minutes: 12 description: "AI Agent Memory Solved: The Stateless PRD Pattern" domain: steepworks type: article updated: 2026-03-25
The Ralph Pattern: Stateless Agents Execute 50-Phase Projects Without Context Loss
You've done this. You gave Claude a 10-step project brief. Steps 1 through 4 were sharp. By step 7, the agent started repeating itself. By step 9, it forgot the constraints you set at the beginning. You closed the tab and finished manually.
Now imagine that at iteration 31 of a 39-iteration project. That's when I stopped trying to fix AI agent memory and started designing around it.
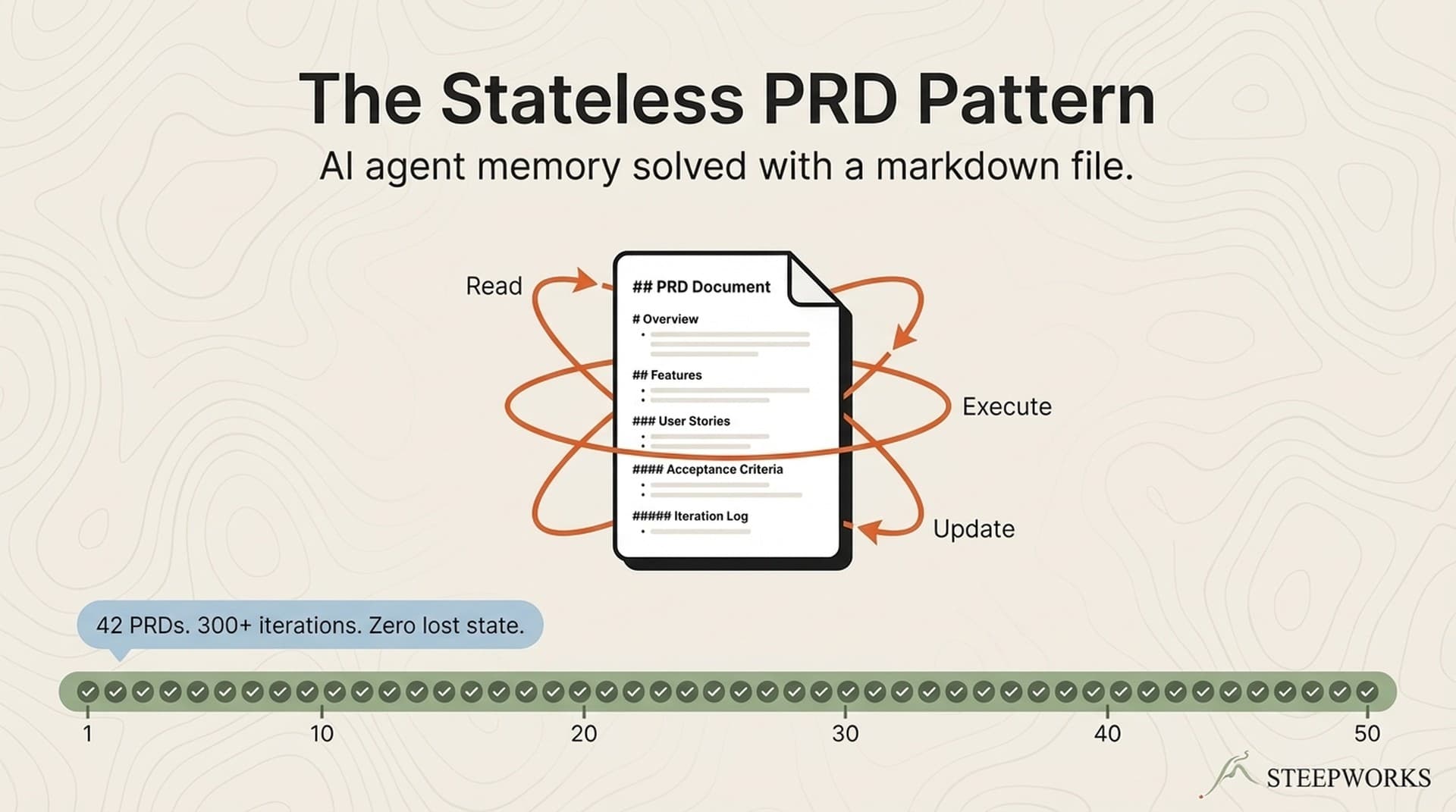
AI agent memory is the problem nobody talks about honestly. Every framework promises persistent context. Every vector store claims total recall. Here's what actually works after 42 projects and 300+ iterations: a markdown file and a protocol. No database. No framework. No infrastructure.
Why Stateful Agents Fail at Step 35
Context Windows Are a Countdown Timer
Every AI agent has a context window. The longer the conversation, the fuller the window. When it fills, two things happen: compaction (the agent summarizes and discards earlier context) or the session ends.
Neither failure is dramatic. The agent doesn't crash. It doesn't throw an error. It drifts. It repeats work it already did. It forgets constraints from twenty messages ago. It proceeds confidently in the wrong direction because the corrective context was compacted away three iterations back.
Zylos Research found performance degrades noticeably after 35 minutes of human interaction time. MemU's analysis puts it bluntly: 65% of enterprise AI agent failures trace to context drift or memory loss, with roughly 2% quality degradation per step.
Two percent per step sounds manageable until you do the math. At step 15, you've lost a quarter of your quality. At step 35, the agent operates at less than 50% of step-1 accuracy. That's not a rounding error. That's a broken execution model.
The Industry Response: Compress and Pray
The standard solutions are infrastructure plays. Vector databases — Redis, Pinecone. Memory frameworks — Mem0, Zep, LangGraph. Platform-level compaction from Claude and OpenAI. Even OpenAI's developers blog devotes space to compaction tips, which tells you how unsolved this is at the platform level.
These tools solve retrieval. "Remember this fact from three weeks ago." They don't solve execution continuity — "remember that you're on step 7 of 12, you completed steps 1 through 6 with these outputs, and step 8 depends on what you did in step 4."
Execution state is different from memory. Memory is retrieval. Execution state is: where am I, what did I just do, what comes next. No amount of vector embedding closes that gap.
The Ralph Pattern — PRD as Memory
The Core Idea
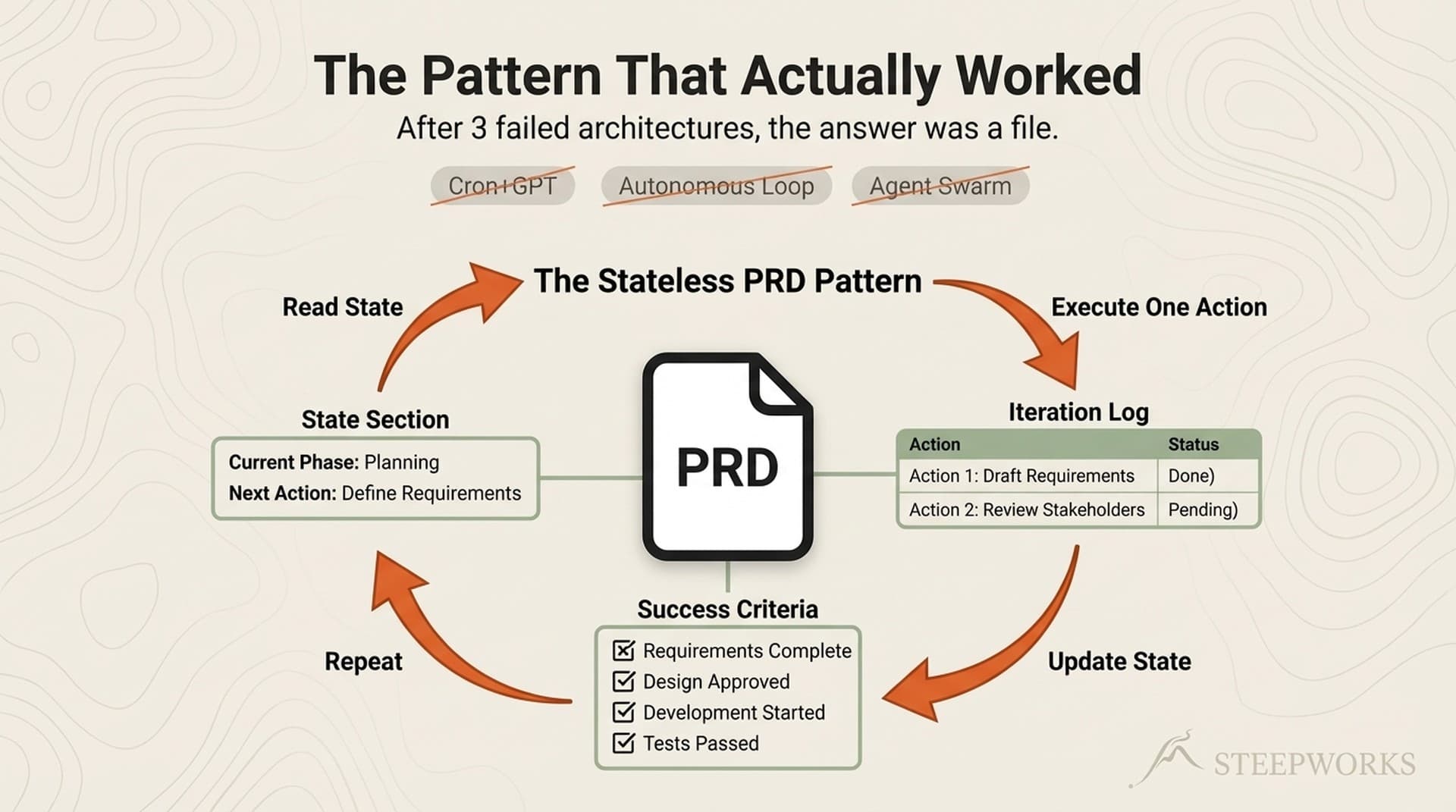
Four sentences. The agent is stateless. Every invocation starts with zero context. All state lives in a single markdown file — the PRD. Each invocation: read state from file, execute one action, update state in file, exit.
The file survives compaction. It survives session breaks. It survives agent handoffs and model switches. The file is the memory.
Why a File and Not a Database
A markdown file in git is the simplest possible persistence layer. No infrastructure to maintain. No connection strings. No schema migrations. No cold-start latency.
Git gives you version history for free. Every state change is a commit. You can diff any two iterations. When something goes wrong, you open the file and see exactly where the agent stopped and why. Try that forensic analysis with a Redis key-value pair.
The file is portable. Switch from Claude to GPT to Gemini mid-project — the file doesn't care. No vendor lock-in. No SDK dependency.
My examples use markdown in git because that's my workflow. But you could use a Google Doc, a Notion page, or a text file on your desktop. The format doesn't matter. What matters is that the agent reads the file at the start and updates it at the end. That's the entire contract.
"But I Already Track Projects in Notion"
Fair question.
In your current workflow, you open Notion, read where the project stands, then re-explain that state to the agent every session. "Remember, we're on step 7. Here's what happened in steps 1 through 6." You're the translation layer between your tracker and the agent's context.
In this pattern, the file IS the prompt context. The agent reads it directly. No re-explanation. The difference isn't the format — it's who reads the tracker. When the agent reads state on its own, you eliminate the re-explanation tax. That tax is bigger than you think — I spent 15-20% of my agent interaction time on context re-loading before I built this.
What the PRD File Contains
Each section does a job:
- Metadata: Project name, dates, owner.
- Objective: What we're building and why. Re-read every iteration to stay anchored.
- Success Criteria: Checkboxes. Unambiguous. "Done" means every box checked.
- Phases: Each has an outcome, actions, and a verification method. Verification is critical — it's how the agent knows a phase is complete, not just "feels done."
- State Section: Current phase. Iteration count. Last action. Next action. Blockers. The agent reads this first every invocation. In 50 characters, it knows exactly where it is.
- Iteration Log: Every action taken. Date, phase, action, result, notes.
- Running Learnings: Compressed operational insights that accumulate across iterations. "Phase 3 files are larger than expected — use extract-then-assemble." "The frontmatter parser chokes on nested quotes." These survive compaction because they live in the file.
- Escape Hatches: Stuck detection thresholds. When to stop trying.
Running Learnings is the section people underestimate. It's where the project accumulates wisdom across iterations — operational insight that would normally live in a senior engineer's head. Except here it survives across sessions, days, and model switches.
The Iteration Protocol — One Action, Every Time
The Essence
The agent reads state from a file. It executes one action. It writes state back to the file. Everything below refines this core loop.
The Full Protocol
- Pre-flight. Verify context budget, tool availability, scope boundary, running learnings.
- Read PRD. Parse success criteria, state section, iteration log.
- Consult skills. If the PRD maps a skill to this phase, use it. Don't improvise when a proven approach exists.
- Assess state. Current phase, iteration count, next action, blockers. Five-second orientation.
- Execute ONE action. Single file read or write. Single command. Single verification. Not two.
- Update state. Write new state. Increment iteration count.
- Update log. Add a row. Date, phase, action, result, notes.
- Output signal. CONTINUE, TASK_COMPLETE, or BLOCKED_NEED_HUMAN.
Eight steps sounds heavy. But steps 2-4 take 10 seconds — reading and orienting. Steps 6-7 take 10 seconds — writing a few lines. The real work is step 5. Everything else prevents the drift that kills projects at step 35.
Why "One Action" Makes It Work
The temptation is always to batch. "I'll do steps 5, 6, and 7 in one pass." I've tried this. Many times. This is how you lose work.
One action means one commit. One rollback point. If it fails, you know exactly what failed. When you batch three actions and something breaks, you're debugging a mystery.
One action means the context window never fills. You read state, do one thing, write state. The conversation is 3 messages, not 300. Compaction never triggers.
One action means trivial handoffs. Any agent — different model, different session, different day — picks up the file and continues. The file IS the transfer. I've switched models mid-project without losing a single iteration.
Phase Boundaries — The Checkpoint System
When a phase completes, three things happen atomically: state updates, the log records the transition, and everything commits to version control.
The Phase Handoff captures context the next phase needs: what was produced, decisions that constrain upcoming work, specific values required. Without it, phase 4 has no idea what phase 3 decided.
Optional log trimming: if the iteration log exceeds 30 rows, compress older entries into a summary. Recent history stays intact. Older entries are already in version history.
This is why a 39-iteration project works. Each phase boundary is a durable checkpoint. Compaction can't erase it because it's in the file, not the conversation.
Escape Hatches — When to Stop Trying
Most agent systems skip this. It saves the most time. (professional Claude Code implementation)
Same action fails 3 times. Stop. The action is mis-scoped. Decompose into smaller actions. (See also: ralph executor)
No phase progress in 5 iterations. Something is structurally wrong — scope too large, verification unclear, dependency missing. This is a planning problem. Escalate. (See also: produce content)
Total iterations hit maximum. Scope was underestimated. Stop, summarize what's done, document what remains, request human review. Partial completion with a clear handoff beats an agent spinning indefinitely.
Blameless Failure Framing
When the agent gets stuck, the instinct is blame. "It couldn't do it." "It's not smart enough." (free setup guide)
The Ralph pattern reframes: not "the agent failed" but "the phase scope exceeds the iteration budget." Not "the agent couldn't handle the data" but "source material exceeds the context window — switch to extract-then-assemble." Not "the agent didn't finish" but "verification method undefined."
Blameless framing produces better fixes. "The agent failed" leads to "try harder" or "buy a bigger model." "The phase is too large" leads to "split into three smaller phases." The first fix is a coin flip. The second actually works.
The Time-Box Rule
If a single action takes disproportionately long — reading too many files, generating excessive content — the action is mis-scoped.
After 3 failed attempts: stop. Decompose into 2-3 smaller actions. Log the decomposition. Frame the original as "too broad for single iteration." This prevents the death spiral where the agent retries a broken action with increasing desperation.
Context Strategy — Three Modes
Not every phase has the same data footprint. The protocol declares a context strategy per phase at planning time.
Small Batch — Direct Mode
Source material under 3,000 lines. Read everything directly. Most 5-phase projects live here.
Medium Batch — Extract-Then-Assemble
Source material between 3,000 and 6,000 lines. Before the main action, extract key facts into a compressed working note under 500 lines. Then execute using only the working note.
Real example: a knowledge graph migration needed 50+ documents for the current schema. Instead of loading all 50, the agent extracted 12 relevant schema facts into a 200-line working note. A 96% context reduction, and the extraction itself was a single iteration.
Large Batch — Map-Reduce
Over 6,000 lines. The phase MUST be MAP sub-phases (process chunks independently) plus a REDUCE phase (combine results). If not structured this way, the protocol blocks and requests restructuring. A hard constraint — I learned this the hard way before making it a rule.
Why Context Strategy Is Declared, Not Discovered
The mode is set at PRD creation, per phase. Not at runtime.
Runtime context assessment burns context. By the time the agent realizes the phase is too large, it's already loaded too much material. The window is half full before real work starts. Declaring upfront means the agent starts with the right approach.
Anthropic's compaction cookbook acknowledges this at the platform level. The Ralph pattern addresses it at the protocol level — before the agent touches a file.
Real Projects — 42 PRDs
The SEO Cascade — 14 City Pages in One PRD
Location-specific SEO pages for 14 cities. Each needed city-specific event data, venue information, keyword optimization, and cross-linking. One PRD, 14 phases, 14+ iterations. When a session ended mid-cascade, the next session found "7 of 14 cities complete" and continued with city 8. No re-explanation.
The Knowledge Graph Migration — 4,700 Files
Six phases with estimated iteration budgets. Running Learnings earned its keep: "The YAML parser fails on nested double quotes — use single quotes." "Archive domain has inconsistent date formats — normalize on read." "Batch size of 50 files keeps context under budget." These survived across sessions and days. An agent starting Tuesday morning had every insight from Friday afternoon. No briefing needed.
The 39-Iteration Stress Test
25 source documents across 6 traditions. Five phases: extraction (25 iterations), thematic synthesis (7), cross-tradition analysis (3), validation (2), final assembly (2). The extraction phase alone was 25 iterations — each reading one document, extracting structured data, writing output, updating state. Iteration 25 had exactly as much context awareness as iteration 1. Without this pattern, the project would have died at iteration 12.
What 42 PRDs Taught Me About Scope
PRDs under 5 phases complete almost always. Over 10 phases, you need careful context strategy — you'll hit at least one phase that exceeds direct mode.
Escape hatches trigger most on phases with unclear verification. "Make it good" isn't verification. "Grep for X and confirm Y rows" is.
Running Learnings are the highest-ROI section. A single learning — "always check frontmatter before writing" — saved 5-10 iterations across subsequent PRDs. Compounding knowledge, captured in a file.
Related: How I Built a 300-File Instruction System That 3 AI Agents Share — the instruction layer the Ralph pattern executes against.
Building Your Own
You don't need 42 PRDs to start. You need one file and one constraint.
The file. A markdown document with three sections: (1) what you're accomplishing — success criteria as checkboxes, (2) where you are — current phase, last action, next action, (3) what happened — an iteration log.
The constraint. Tell the agent: read the file, execute ONE action, update the file, stop.
Your first project. Pick something with 5-8 clear steps. A content series. A data cleanup with a checklist. An audit where "done" means every item reviewed.
Add later. Escape hatches after your first stuck experience. Running learnings after your first repeated mistake. Context strategy after your first overflow. Each feature exists because something broke without it.
What NOT to do. Don't build the full protocol on day one. It evolved over 42 PRDs and 3+ months. Start simple. Add complexity when the simple version fails.
Team adoption. This doesn't require technical skills. It requires discipline — reading the file before starting, updating when finished. I've seen non-technical operators pick it up in one session.
Scope caveat. Works for discrete, multi-step projects with clear "done" criteria. Doesn't work for real-time conversations, streaming workflows, or subjective endpoints.
The minimum experiment. One project. 30 minutes to set up the file, plus execution time you'd spend anyway. If it works, you've solved multi-step AI workflows. If not, you've lost 30 minutes.
Related: Systems Over Tactics: Why Most AI Implementations Fail at Month 3 — why a system like this compounds where individual tools don't.
The Ralph Pattern Is One Layer — Here's What Sits Around It
Stateless iteration solves the single-project memory problem. But a system that runs 42 PRDs across 8 workstreams over months generates a different kind of knowledge — patterns that apply across projects, not just within one. The Ralph pattern doesn't capture those on its own. Three other mechanisms do.
Weekly repo audits and learning rules. Every week, an automated audit reads the git history, scans for recurring patterns, and extracts "learning rules" — operational insights that apply broadly. Example: "PostgREST neq.expired filter silently excludes NULL values — always account for NULLs." That rule was discovered during one PRD, extracted by the weekly audit, and now loads automatically for every agent working with database queries. There are 8 active learning rules right now. They compound — each week's audit builds on the last.
Cross-workstream insights. The audit also detects patterns that span workstreams. A newsletter pipeline improvement that affects content quality. A database schema change that impacts SEO page generation. These get logged as insights with a pending review status. I review them, approve or dismiss, and the approved ones become part of the system's institutional memory. The Ralph pattern handles project memory. The insight system handles organizational memory.
In-loop skill and training doc edits. This is the one that surprised me. When a Ralph iteration discovers something about how a skill should work — a better prompt structure, a missing edge case, a voice standard that needs tightening — the agent edits the skill's reference docs during the iteration. Not after the PRD completes. During. The produce-content skill's 43 reference files didn't grow from a planning session. They grew from dozens of Ralph iterations where the agent encountered a content quality issue, fixed it in the draft, and then updated the training doc so the issue wouldn't recur. The skill gets better as a side effect of doing work. That's the compounding loop: PRD execution → encounter edge case → fix it → update the training doc → next execution starts smarter.
The Ralph pattern is the execution engine. These three mechanisms — weekly audits, cross-workstream insights, in-loop training edits — are the learning system wrapped around it. Without them, you get reliable project execution. With them, the system gets measurably better each week.
The Pattern Is Free
The AI agent memory problem isn't a technology problem. It's a design problem.
Every framework and memory layer tries to make stateful agents smarter — more recall, better embeddings, longer windows. The Ralph pattern asks: what if the agent doesn't need to remember anything? What if the file remembers for it?
42 PRDs. 300+ iterations. Zero lost state.
The pattern costs nothing. A markdown file and a protocol. No vendor, no framework, no infrastructure. Just a file that knows where you are and an agent that reads it every time.
If you're running multi-step AI projects that keep losing context, I'd like to hear what you've tried. The best improvements came from operators who told me what broke. The pattern isn't done evolving — it's just stable enough to share.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.