title: "AI Content Curation: Scaling 1 Agent to 7" slug: scaling-curation-agents seo_keyword: "AI content curation" meta_description: "1 to 7 AI content curation agents over 4 months. Evidence fields cut hallucinations from 15% to 2%. Four mechanisms that prevent quality collapse as you scale." og_description: "Scaling from 1 to 7 curation agents made output worse. Hallucinated evaluations, scoring drift, consensus collapse. Four mechanisms that fixed it across 4 months of iteration." cluster: claude-code-operators author: Victor status: published published_date: 2026-03-25 read_time_minutes: 11 description: "AI Content Curation: Scaling 1 Agent to 7" domain: steepworks type: article updated: 2026-03-25
From 1 Agent to 7: How I Scaled Curation Without Scaling Hallucinations
I had a single Claude agent evaluating 120+ articles per week for a newsletter. It worked — mostly. The picks were reasonable. Then I added a second agent with a different perspective, and the disagreements surfaced articles the single agent had dismissed. So I added a third. Then a fourth. By the time I had five, the system produced worse output than one agent alone.
AI content curation at scale requires something most guides skip: mechanisms that prevent quality from collapsing as complexity grows. More agents should mean better results. In practice, more agents meant more hallucinations, scoring chaos, and newsletters that read like they were curated by committee.
Three problems nearly killed the whole system:
-
Hallucinated evaluations. Agents invented article details. One cited a "benchmark study comparing 12 tools" from a piece that was actually a product announcement. Another fabricated "34% improvement in pipeline velocity" that appeared nowhere in the source.
-
Scoring drift. Every agent inflated scores until everything was a top pick. The rubric meant nothing without anchored examples.
-
Consensus collapse. Agents converged on the same safe picks. Five agents agreeing on everything is more expensive than one agent, not more useful.
The honest take: scaling AI content curation isn't an architecture problem — it's a quality assurance problem. The architecture is easy. Keeping each agent honest as you add more is hard. This is the buildlog of how I solved it — four versions, four months, and the mechanisms that kept hallucinations from scaling alongside the agents.
The Evolution — Four Versions in Four Months
This wasn't a grand design. Four rounds of iteration, each solving one problem and introducing another.
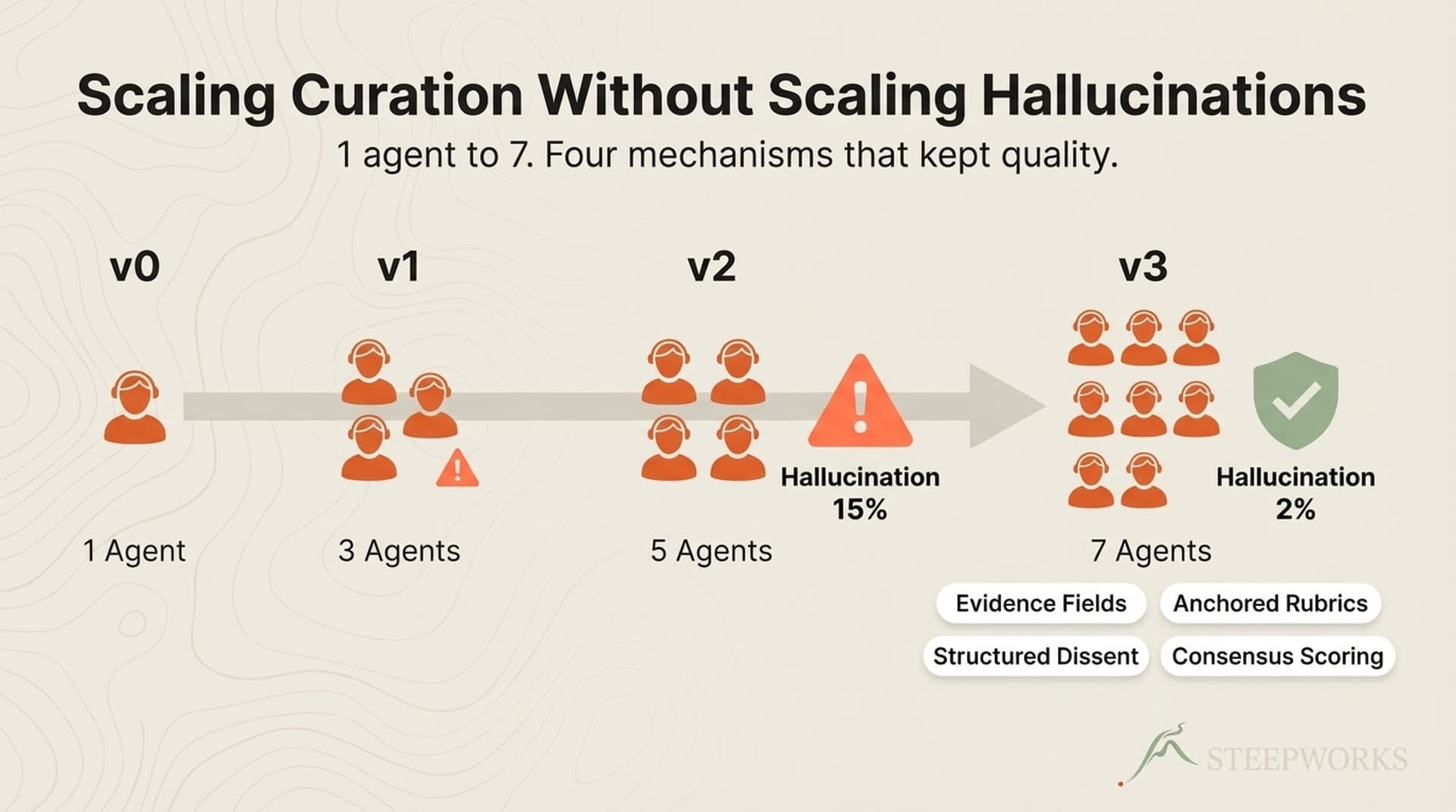
Version 0 — One Agent, One Prompt (Q4 2025)
A single Claude prompt. "Evaluate these articles for a GTM newsletter. Pick the best 8." RSS output from 65+ sources.
It worked for two weeks. By week three, every issue led with the same themes. Recency bias — recent articles got favorable treatment regardless of depth. Hype amplification — bold AI claims got boosted, skeptical pieces got buried. No editorial tension.
What I learned: a single agent can't hold multiple professional perspectives simultaneously. You can ask one persona to be both AI-skeptic and tool-obsessed builder, but you get a muddled middle that hedges everything.
Version 1 — Three Agents, No Coordination (Jan 2026)
Three distinct GTM personas: a builder focused on implementation, a revenue leader focused on pipeline impact, a contrarian who questioned everything. Independent scoring. Weighted average for final picks.
Quality jumped immediately. The contrarian broke the echo chamber. Disagreements surfaced pieces about second-order costs of tool adoption and quiet infrastructure work that mattered to operators.
But two gaps emerged within weeks. Lean-execution content — scrappy, low-budget work that bootstrapped teams do — got overlooked. So did integration and architecture angles. All three personas had enterprise-level blind spots.
Version 2 — Seven Agents, Scoring Chaos (Feb 2026)
Four more personas: a scrappy marketer on constrained budgets, an enterprise closer thinking about deal cycles, a RevOps architect focused on systems, and an editorial moderator.
More coverage. More perspectives. More noise than signal.
Five of seven agents rated nearly everything above 80/100. The moderator couldn't synthesize seven opinions that all said "this is great." Cost jumped. Evaluation time tripled. Newsletter quality dropped because the system couldn't distinguish "good" from "great."
I was spending more on API calls and getting worse results. That's the moment you either fix the fundamentals or go back to one agent and a spreadsheet.
Version 2.1 — The Fixes (Mar 2026)
Three changes saved the system:
- Calibration anchors — concrete examples of what each score level looks like
- Evidence fields — structured separation of verifiable claims from interpretation
- Two-track scoring — human curation architecturally dominant over agent-only picks
Running weekly since early March. The numbers from a real run (2026-03-11): 85 articles evaluated. 7 agents producing 595 individual evaluations. 15 articles advanced to moderated debate. Final output: 8 newsletter picks with full reasoning trails. Every pick traceable to specific evidence.
For the full pipeline architecture — personas, debate protocol, daily ingestion — that's the sibling article on the 7-agent newsletter system. This piece covers what broke and the mechanisms that fixed it.
Hallucination Was the Existential Threat
Don't get me wrong — I expected hallucinations. What I didn't expect was where they'd show up.
Agents didn't make up articles. They made up details about articles. One cited a "benchmark study comparing 12 tools" from a product announcement with no benchmarks. Another invented "34% improvement in pipeline velocity" from thin air. A third described an article's "framework for evaluating AI maturity" when the piece was a founder's personal reflection.
The agents were filling gaps between what articles actually said and what their personas wanted them to say. The Builder, primed to find implementation details, hallucinated implementation details into articles that had none. The Revenue Leader hallucinated metrics.
This is worse than the hallucination problem everyone discusses. When a chatbot hallucinates a fact, a human catches it in conversation. When a curation agent hallucinates its reasoning, the pick still looks plausible — the summary is coherent, but the selection logic was fabricated. The hallucination lives in the evaluation layer, invisible in the output.
The Fix: Evidence Fields
Every evaluation now requires two separate evidence sections:
from_article: Direct quotes or specific data points from the source. Must be verifiable.from_persona: Persona-based reasoning and interpretation. Where the professional lens applies.
The separation makes hallucination visible. If an agent claims benchmark data, it has to produce the quote in from_article. If it can't, validation fails. Persona reasoning in from_persona can be speculative — that's the point of distinct perspectives. But factual grounding has to be real.
This cut hallucinated evaluations from ~15% of outputs to under 2%. Not because the model got smarter — because the schema forced honesty. When you require evidence in a separate field, the model either produces it or doesn't.
Anthropic's work on structured evaluation for AI agents makes the same point: structured evaluation outperforms vibes-based assessment. AWS has documented similar techniques, particularly multi-agent validation and structured output schemas.
Scoring Drift and the Consensus Problem
Hallucination was acute — catastrophic when it happened, identifiable once you knew to look. Scoring drift was chronic. Slow, invisible, and just as destructive.
The Drift Problem
By week three of Version 2, the Builder rated everything above 80. The Contrarian rated 90% as SKIP. The Revenue Leader gave scores of 72-78, a narrow band that made ranking impossible. Every agent had its own interpretation of the scale, and none matched.
The root cause: the rubric defined "interesting" per persona but not what "85 confidence" versus "65 confidence" looked like concretely. Without anchors, each agent developed its own calibration — inflating over time because LLMs default to agreeable. Multiply that across seven agents and everything is above average.
The Fix: Calibration Anchors
Each agent's prompt now includes three concrete examples: (professional Claude Code implementation)
- STRONG_PICK at 90+: Original research, actionable framework, challenges conventional thinking, production data (See also: social content agent)
- RECOMMEND at 70-79: Solid content, familiar angle, well-executed but not surprising
- SKIP: Surface-level, vendor marketing, no practitioner insight, covered better elsewhere
Concrete examples, not abstract criteria. The anchors reset the baseline every run. Drift can't accumulate because reference points are fixed.
The Consensus Problem
Score inflation was one problem. Worse: five agents agreeing on everything. (free setup guide)
Unanimous AI agreement sounds like validation. It's a sign of failure — agents converging on safe, obvious picks. The interesting editorial decisions live in the disagreements. When the Builder loves something and the Contrarian hates it, that tension makes a curated newsletter worth reading instead of an RSS feed with extra steps.
Two failure modes:
Majority herding. Agents front-loaded agreement in debate rounds. Nobody wanted to dissent. Consensus of politeness, not insight.
Debate degeneracy. Agents collapsed into "I agree with the moderator" instead of defending positions. Three rounds producing zero new information.
The Fix: Structural Adversarialism
The Contrarian has inverted scoring incentives. A STRONG_PICK means the article exposes an under-discussed problem, challenges an industry assumption, or presents counter-evidence. This agent breaks the politeness loop.
The moderator uses forced advocacy: "You flagged integration risk. The Builder says it's overblown. Make your case with evidence." Agents must defend positions when the room disagrees. Not artificial conflict — prevention of artificial harmony.
The Fix: Two-Track Scoring
Track 1 (human-curated — articles I flagged during daily Slack curation): Base score 60/100, plus bonuses for agent agreement, annotation quality, and tension flags.
Track 2 (agent-discovered): Base score 15/100, plus per-agent bonuses, capped at 70/100. No agent-discovered article outranks a human-curated one without exceptional consensus.
This is a design decision about trust. I trust agents to evaluate. I don't trust them to editorialize. The human signal stays dominant by architecture, not accident.
In practice:
Article X — deep piece on data infrastructure for GTM. I flagged it with a note: "underrated, good for the Architect." Track 1 base: 60. Builder RECOMMEND at 75 (+5). Architect STRONG_PICK at 92 (+10). Contrarian CONDITIONAL at 68 (+2). Revenue Leader SKIP (no bonus). Final: 77. Made the newsletter.
Article Y — agent-discovered only. Builder STRONG_PICK at 88 (+8). Revenue Leader RECOMMEND at 74 (+5). Others RECOMMEND (+3 each). Agent total: 15 + 8 + 5 + 3 + 3 + 3 + 3 = 40. Didn't make it. No human signal to validate.
Agents expand my peripheral vision. They don't replace my editorial judgment.
The Architecture That Survived
After four months: independent parallel evaluation, then moderated convergence.
Why parallel evaluation. When agents evaluate in parallel, they can't contaminate each other. I tried sequential evaluation in V1 — each agent saw previous scores. The result: anchoring bias. Second agent's scores clustered within 5 points of the first's. Parallel evaluation eliminated this.
Google Research on scaling agent systems provides backing: multi-agent coordination improves parallelizable tasks but degrades sequential ones.
Moderated convergence. Top 15 articles enter a three-round debate. Round 1: positions. Round 2: the moderator surfaces disagreements and asks agents to address them. Round 3: convergence on a weekly editorial frame. The Editor moderates — the only agent that doesn't score independently.
The weekly thesis. The debate produces a one-sentence editorial frame. From 2026-03-11: "The GTM stack is splitting into two speeds. Most teams can only see one." That emerged from a Builder/Contrarian tension over whether cheap leads are a structural advantage or a vanity metric. A single agent never produces that synthesis. It takes genuine disagreement and a moderator who extracts insight from conflict.
Cost. Daily pipeline infrastructure: ~$6-8/month. Weekly evaluation and debate: meaningful API investment at 85 articles with 7 agents plus 3 debate rounds. Human time: 10-15 minutes/day for curation, 30 minutes/week for final review.
What Transfers Beyond Newsletters
You probably don't need 7 curation agents. But these patterns apply anywhere a single LLM's judgment determines outcomes and you're uncomfortable with how opaque that judgment is.
Evidence fields — separating verifiable claims from interpretation. Apply to deal review, competitive intel, content approval. Anywhere LLM reasoning needs auditing.
Calibration anchors — concrete score-level examples. Apply to lead scoring, content quality gates, vendor evaluation. Without them, drift is inevitable.
Two-track scoring — human signal architecturally dominant. Apply to any system where AI handles scale but humans handle judgment.
Structural adversarialism — one agent designed to disagree. Apply to deal qualification, campaign post-mortems, product prioritization. Unanimous AI agreement is the most dangerous output.
Parallel evaluation into moderated convergence. Apply to QBRs, roadmap prioritization, board meeting prep. Independent assessment first, structured debate second.
Google Cloud's 2026 AI agent survey found fewer than 1 in 4 organizations have scaled agents to production. The scaling problem isn't building agents. It's keeping them honest. These five mechanisms are what I found that works.
The deeper principle — building systems that compound knowledge rather than just process information — is something I've written about in systems-over-tactics thinking.
When NOT to Build This
I spent four months on this. Most people shouldn't.
A single agent is enough when:
- Fewer than 30 items per cycle
- Simple, stable evaluation criteria
- You can review every pick yourself
Multi-agent earns its complexity when:
- The evaluation genuinely requires multiple perspectives that can't coexist in one prompt
- You're processing 50+ items where full human review is a bottleneck
- False consensus is a real risk
- You need auditable reasoning, not just a ranked list
The honest cost: four months of iteration. Pipeline infrastructure is $6-8/month. Weekly evaluation costs real API money. Human time is 10-15 minutes/day plus 30 minutes/week. If your volume doesn't justify that, a well-prompted single agent with manual review is the right call.
Starting Over, I'd Do This
Start with 3 agents, not 1. The jump from 1 to 3 teaches more about multi-agent dynamics than reading about them.
Add calibration anchors from day one. I lost three weeks of useful data because early runs had no consistent baseline.
Build evidence fields before scaling past 3. At three agents, you can manually spot-check hallucinations. At seven, you can't.
Add the Contrarian first. Unanimous AI agreement usually means they're all making the same mistake with high confidence.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.