title: "AI Marketing Automation: 11 Posts/Day Pipeline" slug: social-content-agent seo_keyword: "AI marketing automation" meta_description: "AI marketing automation: 11 social posts daily from 65+ RSS feeds, 7 templates, 47 anti-slop patterns. Full 6-component buildlog at under /month." og_description: "6-component social content pipeline generating 11 posts daily. 65+ RSS sources, 7 LinkedIn templates, 47 anti-slop patterns, 5 positive voice signals. Under $15/month. Every component documented." cluster: claude-code-operators author: Victor status: published published_date: 2026-03-25 read_time_minutes: 11 description: "AI Marketing Automation: 11 Posts/Day Pipeline" domain: steepworks type: article updated: 2026-03-25
My Social Content Agent Posts 11 Times a Day. Here's Every Component.
I Spent Three Weeks Writing Social Posts by Hand Before I Automated Everything Wrong
Let me clarify what "11 posts a day" means before you close this tab: 5-8 LinkedIn posts and 3-5 X posts generated daily from curated articles, queued across the week. Not blasted. Each one passed through quality gates and held until I approve it. Publishing follows platform-specific timing — 2-3 LinkedIn posts per day max, staggered.
I was curating 5-8 articles a day for a newsletter intelligence pipeline. Each one needed a LinkedIn post and an X post. I wrote them by hand for three weeks. Then I pointed Claude at the articles and asked it to generate posts. The output was technically correct and completely unusable — generic commentary that could have come from any LinkedIn thought-leader account. No voice, no operator perspective, no reason to follow me instead of the article's author.
Buffer handles scheduling. Jasper handles generation. Neither handles the gap between generation and quality — template selection, anti-slop filtering, voice calibration that makes a post sound like you instead of like AI. That gap is the entire system described here.
This is a buildlog of every component I run in production. AI marketing automation as an operator actually builds it — not as a vendor pitches it.
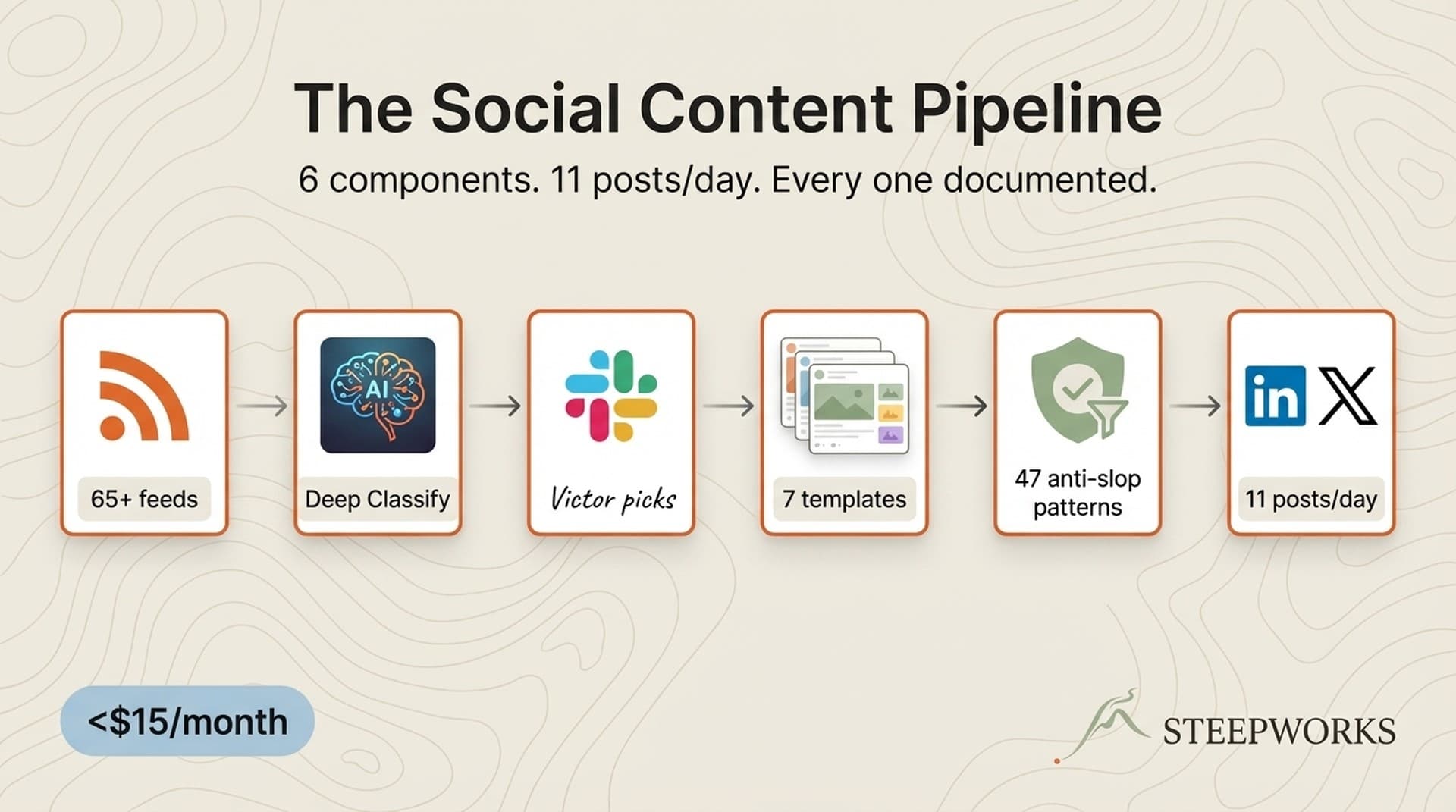
Component 1 — The Data Pipeline (How Articles Become Social Fodder)
The social agent sits downstream of a newsletter intelligence pipeline that already finds and classifies articles. Skip this and you end up writing prompts that say "generate a LinkedIn post about AI." That's how you get slop.
The Ingestion Layer
A Cloudflare Worker runs Monday through Friday, pulling from 65+ RSS feeds. Two-pass AI classification scores every article on relevance from 1 to 10, then deep-classifies anything scoring 5+. Results land in Supabase with structured metadata: content pillar tags, key takeaways, quotable insights, metrics cited, tone assessment, and contrarian signals.
This isn't light tagging. The deep classification extracts the specific data points, quotes, and arguments that make an article worth commenting on. By the time the social agent sees an article, it already knows what's interesting.
The Curation Layer
Every morning, classified articles land in Slack. I review and mark articles with a thumbs-up and a note. The note is the most important input. Without it, the agent writes about the article. With it, the agent writes about what I think about the article. That's the difference between commentary and operator content.
A note like "a good if high-level overview" triggers a different post than "this matches what we've been living — the buying motion is self-directed before anyone talks to us." Short notes produce generic posts, almost 1:1. I learned this the hard way.
What the Agent Receives
The social agent queries Supabase for articles I've picked and annotated. Each record includes: curation ID, article title, source, author, URL, content pillar, AI classification (key takeaways, quotable insight, metrics cited, tone, is_contrarian flag), and my curation note. That structured context separates this from "hey Claude, write me a LinkedIn post."
Cost for the full ingestion pipeline: roughly $6-8/month. Cloudflare free tier, Supabase free tier, Claude API for classification. The expensive part is my attention, not the infrastructure.
For more on the upstream pipeline: How 7 AI Agents Evaluate 120 Articles Weekly for My Newsletter Pipeline.
Component 2 — The Generation Pipeline (From Curation to Platform-Native Copy)
I rebuilt this three times before it worked.
The PRD That Built the Pipeline
The social content pipeline was designed through a formal PRD: 5 phases, 18 ordered deliverables. Phase 1 built platform knowledge bases from research covering 1.8 million to 18.8 million posts. Phase 2 created the hook library and template system. Phase 3 wired everything into generation agents. Phase 4 added positive pattern scoring. Phase 5 archived research and extracted reusable copywriting frameworks.
The first version had one hardcoded prompt template per platform. Every post sounded the same by day 3. The root cause: the skill reference files — where copywriting knowledge lived — and the Python agent prompts — where generation happened — were completely disconnected. The agent never read the skill references. Improving those files had zero effect on output.
The fix: make skill references the canonical source and agents the consumers. One source of truth, loaded at runtime. Before this, two systems drifted apart. After it, improving a reference file immediately improves every agent that loads it.
Template Selection: Scoring, Not Randomizing
The system uses 7 LinkedIn templates: system_reveal, pattern_recognition, honest_disagreement, operator_lesson, data_story, build_log, and commentary (fallback). For X: 4 templates — the_claim, the_reframe, the_build_log, the_pattern.
Selection isn't random. The agent analyzes article characteristics — strong data? Contrarian? Does my note reference build experience? Each characteristic scores templates differently. A has_build_experience signal gives +3 to system_reveal and build_log. An is_contrarian signal gives +3 to honest_disagreement.
The recency penalty matters more than I expected. The agent checks the last 5 posts in queue. If a template was used recently, it gets penalized. Not randomizing — tracking what you've already used and steering away from it.
Hook Selection: 25+ Hooks, 8 Types
The hook is the first two lines on LinkedIn — everything before "see more." If the hook doesn't earn the click, the post doesn't exist.
Hook types map to article characteristics: data-first, contrarian, story lead, pattern recognition, question, build-in-public, myth-bust, operator lesson. The hook library encodes copywriting craft drawn from 232 frameworks, proven opening patterns, and social-specific format research. Each hook includes the psychology principle behind it and an anti-pattern warning.
Platform-Native Generation
LinkedIn and X are not the same post. The first version generated one post and reformatted for each platform. LinkedIn posts compressed into X posts read like summaries. X posts expanded into LinkedIn read like padding. Each platform needs its own prompt, structure, and voice register.
LinkedIn enforces operator-first framing: "This is NOT a post about the article. This is a post about what I've built, tested, or learned — triggered by the article." Target: 1,300-1,900 characters. No links in body. Designed for saves.
X is sharper and more opinionated. Single tweet, 280-500 characters.
The platform research is specific. LinkedIn saves carry 5-10x the algorithmic weight of likes, based on analysis of 3 million+ posts. Link posts lose 60% reach. On X, author reply chains are worth 150x a like per the open-sourced algorithm. Bookmarks are 20x. These numbers are encoded directly in generation rules — the agent writes for saves and bookmarks, not link clicks.
For the tool landscape: Buffer's overview of 14 AI tools for social media content creation.
The Copywriting Skill
The generation pipeline draws from a codified copywriting skill: 7 inviolable principles including specificity creates believability, benefits over features, customer language over vendor language, emotional truth first, ruthless concision. These aren't suggestions. They're enforced — the system prompt embeds them, quality gates check for them.
The skill includes perspectives from 12 copywriting masters used as thinking modes: Ogilvy the researcher, Hopkins the scientist, Halbert the storyteller, Schwartz the psychologist, Caples the tester, and 7 modern practitioners. Masters often disagree, and resolving their tensions is where craft lives. Hopkins wants a specific number; Halbert says it sounds robotic. Resolution: a number that sounds human — "I built 11 agents. Three failed." The data_story template channels Hopkins. The operator_lesson template channels Halbert.
For short-form, compression mechanics matter. Techniques from 50,000+ high-performing tweets: monosyllabic endings ("The work is the proof"), landing on nouns, negation flips ("Don't sell. Teach."), matched meter ("Small bets. Big systems."), and colon pivots — roughly 33% higher engagement.
Component 3 — The Quality Gates (Where Most Systems Fall Apart)
This section separates a production system from every "I automated social media with AI" blog post.
Gate 1: Anti-Slop Regex (47 Patterns)
Every generated post runs through 47 regex patterns. "Revolutionary," "leverage," "synergy," "10x," "crush it," "In today's fast-paced world" — any match triggers full regeneration with explicit avoidance instructions.
These 47 patterns are calibrated from a codified editorial framework defining pattern groups A through G with a minimum combined score of 7.5/10.
Gate 2: Structural Slop Detection
Beyond individual words: dramatic fragment triplets and constructions like "Here's what nobody's saying" are the tells that survive word-level filtering — patterns readers sense even when they can't articulate what feels off.
Gate 3: Positive Pattern Scoring
Killing slop isn't enough. The post needs to sound like me. Five signals: specificity (numbers and data), uncertainty acknowledgment, personal experience reference, teaching depth, exploration markers. LinkedIn posts need 3/5 and must pass specificity. X posts need 2/5.
What Happens When Gates Fail
Anti-slop catches a violation — full regeneration with violations as avoidance instructions. Positive patterns score too low — the agent revises the existing post rather than starting over.
A Real Before-and-After
From a March 20 run:
Raw output (no gates): A LinkedIn post opening with "Brendan Short published a fascinating FAQ on GTM Engineering..." — commentator voice, no operator perspective. "Fascinating" does no work. The article author is in the driver's seat, not me.
After anti-slop gate: "Fascinating" flagged. Structural detection catches more tells. Regenerated. (See also: social content agent)
After positive pattern revision plus my edit: Opens from experience — "From what I'm seeing in conversations with operators, the practical questions are getting more granular fast..." — specific data, uncertainty, and personal experience signals present. My edit added a connection to something I've built that the agent didn't know about. (See also: claude md)
A Transferable Checklist
Even if you never automate this, the five signals work as an editorial checklist. Before publishing any post: Does it have specific data? Acknowledge uncertainty? Reference personal experience? Teach something? Explore an open question? 3/5 is the floor. (professional Claude Code implementation)
Edelman's B2B Thought Leadership Impact Report found 86% of B2B decision-makers prefer content that challenges their thinking.
Component 4 — Tone of Voice as Infrastructure
Voice is not a vibe check. It's a configuration file.
The STEEPWORKS voice is defined in a reference document loaded at runtime: practitioner not theorist, patient not hype-driven, systems-minded not superficial, humble not authoritative, specific not vague. Each characteristic has "what it sounds like" and "what it doesn't sound like." That's how you make voice transferable between humans and agents. (free setup guide)
The Controlled Vocabulary
Preferred verbs: brew, steep, climb, orient, distill, build, synthesize, extract, compound. Preferred nouns: ember, range, trail, contour, pattern, terrain, summit, cycle, loop. Explicit avoid list: hustle culture terms, corporate jargon, guru language, hype words. The anti-slop gate's 47 patterns draw partly from this list. Voice standards feed quality gates.
Phase-Specific Tone
Content energy matches a five-stage cycle. Intention: curious, sparking — "What if..." Research: patient — "I let it sit..." Execution: active — "When I tried..." Synthesis: clear — "From up here..." Teaching: generous — "Here's what worked..."
Voice Enforcement in the Pipeline
The system prompt embeds the Reflective Operator identity: "You are Victor, a 15-year GTM operator who builds AI-native revenue systems daily." Not a social media manager. An operator who shares what he learned. The operator test: "What have I personally built, tested, or experienced that connects to this?" If the answer is nothing, reframe through a specific system or decision.
Anti-patterns were added after specific generated posts exhibited them and passed the regex gate — proof that voice enforcement requires both regex and prompt-level avoidance working together.
Component 5 — The Approval Flow and Posting Mechanism
The agent generates and queues. I review and approve. Not fully autonomous — by design.
Queue Architecture
Each post gets its own directory: {date}_{slug}/linkedin.md, x.md, first_comment.md, and metadata.json. Metadata tracks source article, template used, hooks selected, article characteristics, quality scores. The queue is a git repo. Every post is version-controlled.
Slack as the Review Interface
Each post lands in Slack as a Block Kit message with copy-pasteable content. LinkedIn and X side by side. I review where I already work.
Rejected posts move to a rejected subdirectory for analysis — I want to know what the agent got wrong, not just that it got something wrong.
Why Not Fully Autonomous
I could remove the approval step. Quality gates catch most problems. But the posts that pass all gates and still miss the mark are the ones where the article triggered a connection to something I experienced that the agent doesn't know about. Those edits — adding a connection to a real system I built, a conversation I had, a deployment that broke — are where the human value lives. Removing me from the loop would save 15 minutes a day and cost me the best 20% of my content.
Posting Cadence
Approved posts publish via a separate script. The agent generates; a different process publishes. Posts spread across the week — Wednesday lead, Thursday secondary, Friday recap, Monday thread, Tuesday remaining.
For more on skill architecture: I Built 52 Claude Code Skills. Here's the Anatomy of the 7 That Ship Daily.
Component 6 — The Infrastructure
Python agent: 683 lines. Extends a base agent handling Supabase queries, Claude API calls, logging, queue management, Slack notifications.
Claude for generation: Sonnet, not Opus — cost management. 1,500 token limit for LinkedIn, 600 for X.
Supabase for state: Curations, article metadata, social_posted_at timestamps.
Slack for notification: Webhook-based. Block Kit messages.
File system for queue: Git-tracked directory. Each post is a directory with markdown and JSON.
Total monthly cost: Claude API roughly $2-4/month. Supabase free tier. Slack free tier. Cloudflare free tier for upstream ingestion. Under $15/month for the full pipeline.
For a simpler scheduling-focused approach: Stormy AI's guide to automating social media with Claude Code and Blotato. If you need scheduling, use Blotato or Buffer. If you need generation that sounds like you, you need this pipeline.
What Broke and What I'd Change
Every Post Sounded the Same (Day 3)
March 22, three days in. I was reviewing 6 LinkedIn posts and every one opened with "I've been watching..." Every X post was the same hot-take structure. That's when I built the recency penalty system.
The Anti-Slop Gate Was Too Aggressive (Day 1)
The first regex set included "optimize" and "scale" — words I use naturally in technical contexts. Day 1, the agent rejected a post about scaling curation agents because "scale" triggered the filter. I had to calibrate slop patterns to catch corporate jargon while allowing legitimate technical vocabulary. The current 47 patterns are the result.
The Skills-to-Agent Disconnect
The copywriting skill had deep knowledge — 7 principles, 12 master perspectives, hook patterns, compression techniques — but the Python agent never read any of it. The most important architectural decision: making skill references the canonical source and building a runtime loader so agents consume the same knowledge base the interactive skill uses.
Note Length Matters
Short notes ("good overview") produce generic posts. Detailed notes ("this matches what we've been living") produce posts that sound like me. The note isn't metadata. It's the creative seed. I've started writing longer curation notes specifically because output quality tracks note quality almost 1:1.
What I'd Change Next
Format rotation needs more intelligence. The recency penalty works for templates but not content themes. If I post about AI hiring data three days running because that's what I curated, the agent doesn't vary the framing. Content-level diversity, not template-level. Working on it.
The Full Architecture
RSS Feeds (65+) -> Cloudflare Worker -> Supabase (classified articles)
|
Slack Daily Digest -> Victor's Curation (notes + picks)
|
daily_social_steepworks.py
|-> Analyze article characteristics
|-> Select template (7 LinkedIn / 4 X) + hooks (25+)
|-> Generate LinkedIn post (Claude Sonnet, 1,500 tokens)
|-> Generate X post (Claude Sonnet, 600 tokens)
|-> Anti-slop gate (47 patterns)
|-> Positive pattern scorer (5 signals, threshold 3/5 LI, 2/5 X)
|-> Voice compliance check (controlled vocabulary + anti-patterns)
|-> Save to queue (git-tracked directory)
|-> Slack notification (Block Kit, copy-pasteable)
|
Victor reviews in Slack -> Approve / Reject / Edit
|
publish_social.py -> LinkedIn API + X API
Total pipeline cost: Under $15/month.
My daily time investment: 10-15 minutes curation, 10-15 minutes review.
If you're spending 8-10 hours a week on social content, the math is straightforward. If you're spending 2 hours, the ROI is thinner but the quality improvement might justify it.
Don't get me wrong — this system runs one voice because I'm a solo operator. Scaling to a team means N system prompts with N voice profiles, N anti-slop calibrations, N positive-pattern definitions. The architecture supports it — voice is a configuration parameter, not hard-coded. But I haven't tested team-scale. If you manage a content team of 6, this is a pattern to adapt, not a turnkey solution.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.