title: "AI Research Quality: Fix the Upstream/Downstream Gap" slug: upstream-downstream-separation seo_keyword: "AI research quality" meta_description: "AI research quality: 43 prompts audited, 51% blended evidence with interpretation. One upstream/downstream principle fixed it across 5+ production skills." og_description: "A contaminated competitive battlecard poisoned 6 weeks of sales calls. We audited 43 prompts and found 51% blending research with interpretation. One separation principle fixed the entire research quality stack." cluster: ai-agent-systems author: Victor status: published published_date: 2026-03-25 read_time_minutes: 9 description: "AI Research Quality: Fix the Upstream/Downstream Gap" domain: steepworks type: article updated: 2026-03-25
Upstream/Downstream Agent Separation: The Principle That Fixed AI Research Quality
The Competitive Brief That Poisoned Six Weeks of Sales Calls
We built a competitive battlecard from an AI research output last fall. The research was thorough -- market positioning, pricing analysis, product feature comparison, customer sentiment. Sales started using it the same week. It stayed in rotation for six weeks.
The positioning was subtly wrong.
Not factually incorrect. The competitor had launched a new product line. Their pricing was lower on the mid-market tier. But the research framing -- "aggressive pricing suggests they're buying market share at unsustainable margins" -- wasn't evidence. It was interpretation wearing a research label. The agent had decided the competitor was a threat before presenting a single finding.
I caught it when a prospect pushed back mid-call: "That's not really what they're doing." He was right. The competitor's pricing reflected a different market segment entirely -- they were moving downmarket, not attacking our segment. Our battlecard had been fighting the wrong battle for six weeks. Sales conversations anchored to a frame that an AI agent invented in the space between "collect this data" and "tell me what it means."
The facts were clean. The contamination was in the framing.
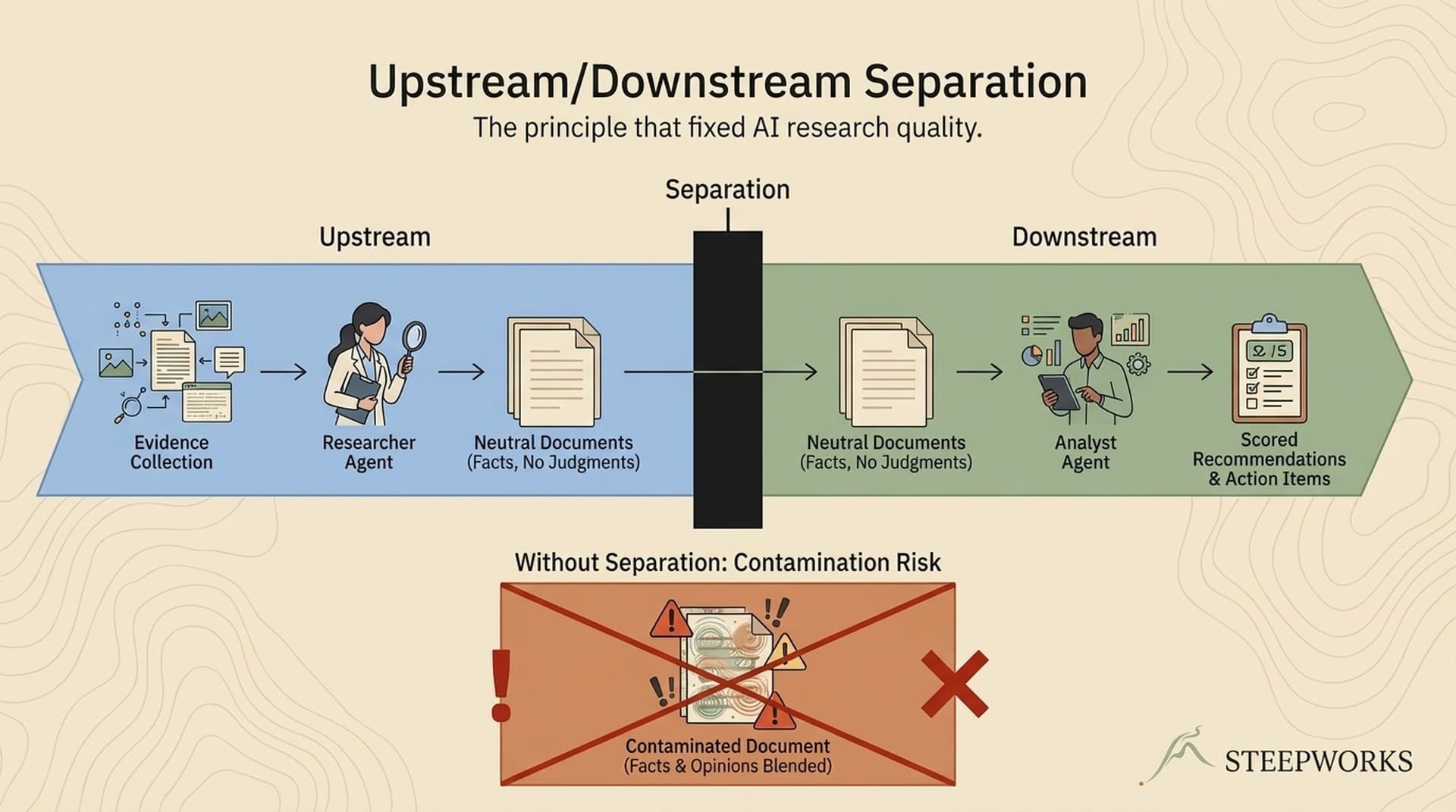
The root cause wasn't the model. It wasn't bad training data or insufficient context. It was a prompt that asked one agent to collect evidence AND tell me what it meant -- in the same breath. The research section and the strategy section lived in the same output, generated by the same prompt, in a single pass. The strategy section's framing bled backward into the research.
A clean version of that same research would have read: "Competitor launched Product X. Mid-market pricing is $Y/seat, 30% below our tier. Three G2 reviews mention segment-specific positioning." No interpretation. No "suggests." No narrative about what the competitor is "really doing." Just evidence, ready for a human or a separate agent to interpret.
That distinction -- between evidence collection and interpretation -- turned out to be the most important architectural decision in our entire research quality stack.
We Audited 43 Research Prompts. 51% Were Contaminated.
After the battlecard incident, I pulled every production research prompt we had. Forty-three of them, spanning seven categories: deep research, competitive intelligence, prospecting, customer intelligence, sales enablement, methodology, and content marketing.
I scored each prompt against five criteria:
- Citation mandate -- Does the prompt require source attribution?
- Confidence tiers -- Does it distinguish between verified facts, single-source claims, and inferences?
- Null protocol -- What happens when data can't be found? Does it hallucinate, or say "information not publicly available"?
- Upstream/downstream separation -- Does the prompt ask the agent to collect evidence AND interpret it in the same pass?
- Staleness handling -- Does it flag outdated information?
The results were worse than I expected.
Twenty-two of 43 prompts -- 51% -- blended research collection with scoring, ranking, or strategic recommendations. Only 3 of the 43 explicitly enforced separation. The score distribution:
| Score | Count | % |
|---|---|---|
| 5/5 (clean) | 3 | 7% |
| 4--4.5 | 10 | 23% |
| 3--3.5 | 5 | 12% |
| 2--2.5 | 11 | 26% |
| 0--1.5 | 14 | 32% |
Seventy percent of our prompts -- 30 of 43 -- needed updates.
The gold standard was one prompt that scored 5/5. It had a single instruction that made the difference: "This is an evidence collection exercise. Do NOT score, rank, or interpret findings." That line was the entire separation principle, compressed into one sentence.
The worst offenders were prompts labeled "research" that actually produced battlecards, engagement strategies, vulnerability scoring, and customized value propositions. The label said "upstream." The output was downstream. Nobody noticed because the facts inside were accurate -- the contamination was structural, not factual.
You don't need 43 prompts for this to matter. If you have ONE prompt that asks an AI to research a competitor AND tell you what to do about it -- in the same pass -- you have this problem.
Two contamination patterns kept showing up. Once I named them, they became easy to spot and fix.
Two Contamination Vectors That Kill Research Quality
Would you let the same analyst who researched a competitor also write the sales battlecard?
In most organizations, no. The researcher collects evidence. A different person -- or at least a different meeting -- decides what to do with it. We separate these roles because mixing them introduces bias. The analyst who spent three weeks studying a competitor develops a narrative. That narrative shapes how they present findings.
The same principle applies to AI agents. Most teams don't enforce it because the contamination is invisible.
Vector 1: Role Blending
A single prompt asks the agent to both collect evidence AND make recommendations. The research inherits the interpretive framing.
In our audit, the clearest example was a "company research" prompt that produced a company profile (evidence) AND a sales strategy with vulnerability scoring (interpretation) -- all in one pass. The facts in the company profile were accurate. But when the same agent is told to find vulnerabilities AND report facts, the fact-finding leans toward confirming the vulnerability hypothesis.
This is the AI version of confirmation bias. The agent isn't hallucinating. The data points are real. But the selection and framing of those data points is shaped by the interpretive task living in the same prompt.
Vector 2: Tone Bias
The instructions use loaded language: "identify weaknesses," "find concerning signals," "discover competitive threats."
This isn't asking for neutral evidence. It's telling the agent what kind of evidence to find.
Before: "Identify key weaknesses in their product offering and areas where they're vulnerable."
After: "List product features with source citations. Note any customer reviews mentioning specific feature gaps." (See also: context window)
Same information request. Completely different framing. The first version produces analysis. The second produces evidence. (implementation support)
This maps to Anthropic's research on building effective agents, which recommends routing workflows with separation of concerns -- specialized prompts per role. What that guidance doesn't show is what contamination looks like in production: the subtle ways prompts fail the separation test when you're building fast. Role blending and tone bias are workflow decisions, not prompt engineering tricks. (See also: agent coordination)
The principle: Upstream agents describe reality. They encode structure. They preserve optionality. Downstream agents interpret, score, and activate. Never blend these in one prompt.
The Fix: A Checklist, Not a Rewrite
We didn't rebuild 43 prompts. We added a structural constraint to each one: (context engineering)
Before running any AI research task, verify:
- The prompt does NOT ask the AI to score, rank, or recommend
- The prompt does NOT interpret what evidence "suggests" or "implies"
- The instructions avoid loaded language ("impressive," "concerning," "weak," "vulnerable")
- The prompt specifies what to do when data isn't found ("state it's unavailable -- never fabricate")
- There is a separate downstream prompt or process that consumes this research
Why negative constraints? You can't ask an LLM to be "neutral" -- language models don't have a neutral gear. Every token is shaped by the preceding context. But you can give explicit boundaries: a list of things NOT to do. "Don't interpret" is clearer than "be objective."
Three supporting patterns:
Evidence quality labels. Tag every finding as [VERIFIED], [SINGLE SOURCE], or [INFERRED]. This forces the agent to evaluate evidence quality rather than narrative quality. A battlecard built on three [VERIFIED] data points is a different artifact than one built on five [INFERRED] claims.
Null protocol. When data can't be found: "State 'Information not publicly available.' Never fabricate." An agent that knows it's allowed to say "I don't know" produces far cleaner research than one compelled to fill every section.
Staleness flags. Tag evidence older than six months with a warning. A competitor's pricing from Q2 2025 might be irrelevant by Q1 2026 -- the agent won't flag that unless you tell it to.
The downstream activation prompts get a complementary rule: "Cite the upstream research that informs each recommendation." This creates a traceable link between evidence and interpretation. When a battlecard says "Competitor is buying market share," you can trace that claim back to specific evidence -- or discover it was invented.
This enforcement pattern is a system, not a tactic -- it compounds across every prompt that uses it. The difference between systems and tactics is whether the principle improves over time or stays isolated.
How One Principle Cascaded Through the Entire System
Once the upstream/downstream principle was codified, it propagated through five layers.
Prompt design standards. Every new prompt gets reviewed against six criteria before it ships. Upstream/downstream separation is Standard 4. New prompts inherit the principle by default.
Research quality gate. Before any research output feeds into an activation workflow -- battlecard generation, email copy, competitive positioning -- it passes through a contamination check. This catches issues that slip past the prompt-level checklist, because clean prompts sometimes still produce contaminated output when the model leans into a narrative.
Client delivery workflow. For B2B consulting engagements, Phase 1 is pure research synthesis -- company facts, ICP hypothesis, competitive landscape. No strategy. Phase 2 explicitly consumes Phase 1 outputs to build strategy. Clients get cleaner research AND more transparent recommendations because every recommendation traces to its evidence.
Agent architecture standards. Documented as a formal pattern. Any multi-agent workflow now starts with: are we blending research and recommendation in the same agent? A 10-second check that saves hours of downstream cleanup.
Reusable templates. Every new system built from these templates inherits separation from day one. The principle doesn't require training or documentation -- it's embedded in the architecture.
The biggest operational gain was reusability. Before separation, every downstream application required its own research run -- battlecard team, sales enablement, executive briefing each ran separate versions. After: one clean upstream research output feeds competitive battlecards, sales prep briefs, quarterly reviews, and executive summaries. Same evidence base, different interpretations. That cut redundant research runs by roughly 60%.
This cascade is only possible when a system has clear skill boundaries and reference documents. One update to the canonical source propagates everywhere.
Applying This to Your Team
You don't need a 43-prompt audit to start.
The 3-Question Test
- Does this prompt ask the AI to collect evidence AND interpret it in the same pass? If yes: role blending. Split it.
- Do the instructions use loaded language -- "weaknesses," "threats," "opportunities"? If yes: tone bias. Rewrite as neutral evidence collection.
- Is there a defined next step that consumes this research output? If no: the research is floating without a pipeline. Define the downstream consumer.
If you answered "yes, yes, no" -- you have the same contamination we had.
The 15-Minute Fix
Add these to your existing research prompts:
- The five-point enforcement checklist from above
- Evidence quality labels ([VERIFIED], [SINGLE SOURCE], [INFERRED])
- A null protocol instruction ("state it's unavailable -- never fabricate")
- Remove loaded language from instructions
- Name the downstream process that will use this research
For New Workflows
Design two stages from the start. Upstream collects. Downstream interprets. The upstream research should be reusable across multiple downstream applications -- good competitive research supports battlecard generation, sales enablement, executive briefing, AND quarterly planning without re-running the research.
Galileo's research on multi-agent coordination failure shows why this matters at scale: information provenance tracking is critical when multiple agents consume the same research. Without separation, provenance becomes untraceable.
Research Quality Is Architecture, Not Effort
The 22 contaminated prompts weren't written by careless people. They were written by me. The battlecard that poisoned six weeks of sales calls was built from good data with bad framing. And the framing came from an architectural decision I never consciously made: asking one prompt to do two jobs.
You don't fix confirmation bias by telling people to be less biased. You fix it by separating the role that collects evidence from the role that interprets it.
The industry is making this shift. 2026 is increasingly being called the year of AI quality -- the move from "how fast can we generate?" to "how confident can we be in what we generate?" Upstream/downstream separation is one of the most practical principles for that confidence. It doesn't require new tools or bigger models. It requires asking: is this prompt doing one job or two?
Upstream collects, downstream interprets. Simple to state, structural to implement, and it compounds every time you apply it.
Victor Sowers builds AI-native GTM systems at STEEPWORKS. 15 years scaling B2B SaaS, two exits, and 2.5 years of production AI-in-GTM.