Most teams adopt AI as a productivity layer. Take your existing workflow, add AI, go faster. Write emails quicker. Summarize meetings. Generate first drafts.
That's fine. It works. But it has a ceiling.
The ceiling is that your workflow was designed for humans. AI operating inside a human workflow inherits all the constraints of that workflow — the handoffs, the context loss between tools, the judgment calls that eat three hours every week.
I went the other direction. Instead of adding AI to existing workflows, I built a GTM function on AI-native architecture from the start. Repeatable processes became executable documents. Judgment calls became codified skills with built-in quality gates. Institutional knowledge became a structured graph that agents can actually navigate.
The thesis: if you build the right infrastructure, a small team can sustain work that used to require departmental headcount.
This page is the index. Each system links to detailed buildlogs — engineering notebooks, not marketing content. Specific architectures, specific failures, specific numbers.
Executable PRDs
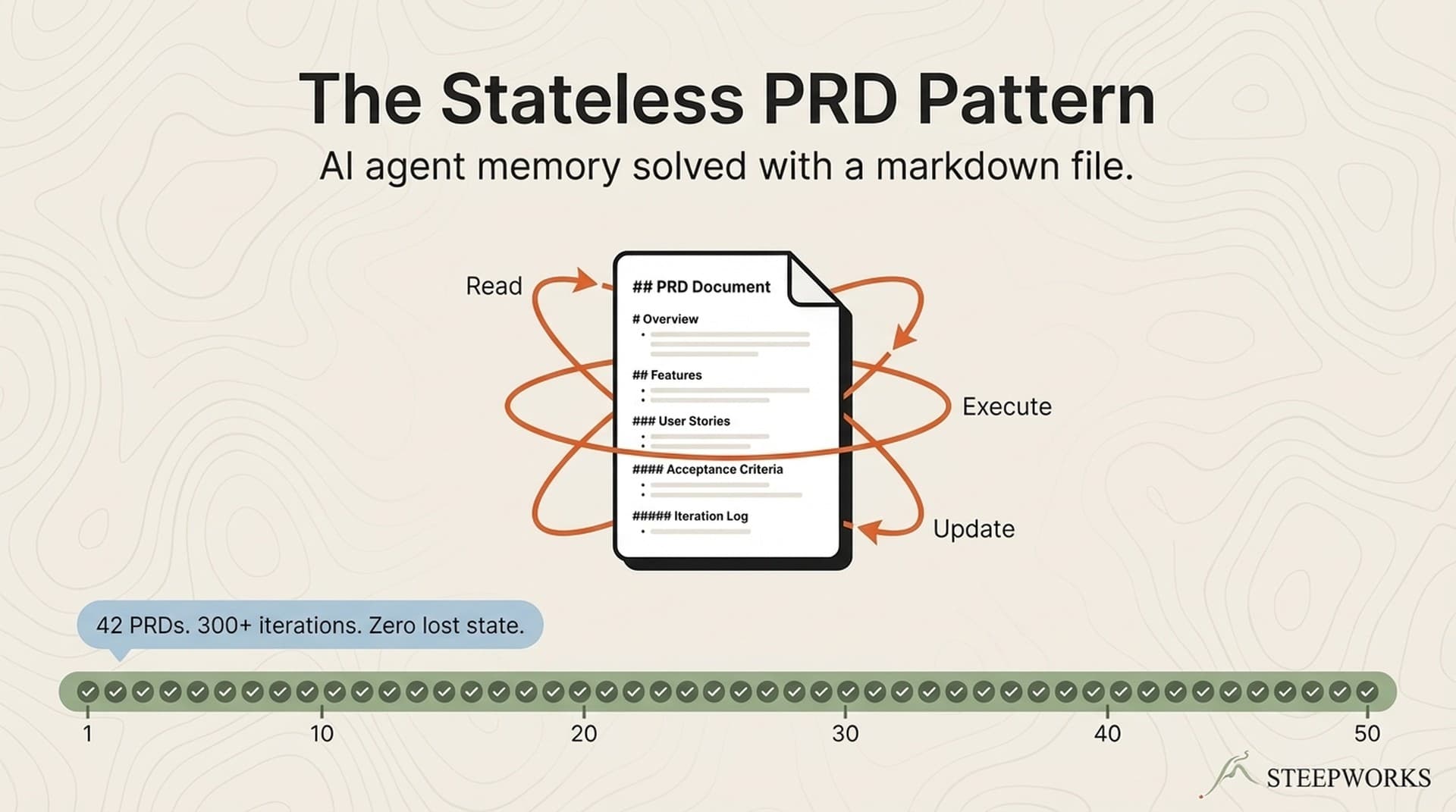
100+ PRDs. Not planning documents — executable state machines. Each one has phases, success criteria, escape hatches, and an iteration log. An AI agent reads the file, executes one action, updates the file, and loops until all success criteria pass. Some ran 21 iterations across multiple days. One PRD coordinated a full website launch across multiple agents — each checking off tasks in a shared file, no orchestrator needed.
The core pattern is file-based state. The document IS the memory. Every iteration writes its result back to the PRD, so the agent never loses context — even across sessions, even after the conversation compacts. No database. No API. Just markdown.
Buildlogs:
-
The Document Is the Memory. The Loop Is the Engine. — The PRD-as-state-machine pattern. How file-based state beats conversation memory. Why one action per iteration matters.
-
AI Agent Memory Solved: The Stateless PRD Pattern — The stateless execution engine. How an agent picks up any PRD mid-flight and advances it without knowing what happened before.
-
Go-Live Checklist PRD: Multi-Agent Website Launch — A real PRD running a real launch. Multiple agents coordinating through a shared checklist file.
Codified Skills
50+ skills. Codified institutional knowledge as executable workflows. A cold email skill that scores drafts on 10 dimensions and stress-tests them against a skeptical buyer persona. A RevOps dashboard that computes zombie deal scores and produces three-layer reports. A prospect research skill that queries CRM before touching a web search.
Of those 50+, roughly a dozen run daily. Another dozen run weekly. The rest are specialized tools for specific situations. The content chain — seven skills from research through publishing — produces a full newsletter edition per week with one human review checkpoint.
Buildlogs:
-
52 Claude Code Skills: Only 7 Ship Daily — Anatomy of a skill library. Which skills survive contact with reality and which don't.
-
The 7-Skill Content Chain — How seven skills chain together to produce a newsletter edition per week. Research, draft, review, edit, image generation, publishing — each skill hands off to the next.
-
Build Your First Claude Code Skill in 30 Minutes — The on-ramp. What a skill file looks like, how to structure it, and the minimum viable version.
Knowledge Graph
Without structure, AI agents drown. Hand one a flat folder of hundreds of files and it either reads too many (burning context on irrelevant content) or reads the wrong ones (producing generic output that could have come from Wikipedia).
The fix is a three-tier hierarchy. Foundation documents define canonical truth — positioning, personas, product capabilities. Domain synthesis documents roll up intelligence from dozens of sources into single navigable references. Detail documents hold the raw material — call transcripts, competitor profiles, market reports. Every document carries YAML frontmatter so agents can query metadata instead of scanning contents. Agents read synthesis first, descend to detail only when they need specific quotes or validation data.
Buildlogs:
-
AI Knowledge Architecture: 4 Layers That Compound — The architectural pattern. How foundation, synthesis, detail, and execution layers relate to each other.
-
Knowledge Graph: 889 Docs, 52 Skills, No Database — The graph in practice. How documents, skills, and metadata connect without a traditional database.
-
Building a Personal Knowledge OS: 4,700 Files Deep — What it looks like at scale. File organization, naming conventions, and the maintenance cost nobody warns you about.
-
Your AI Isn't Dumb. Its Context Window Is Full. — When source material breaks your AI. The MapReduce pattern for knowledge work, and why organizing before splitting matters more than splitting alone.
SEO Operating System
Started from near-zero non-branded presence. Seven workstreams now cover keyword research, content production, technical remediation, programmatic page generation, and continuous monitoring. Over 1,000 programmatic pages generated from a Supabase database in a single sprint.
The SEO system runs on the same infrastructure as everything else. PRDs manage multi-phase audits. Skills generate programmatic pages from structured data. The knowledge graph feeds content briefs with pre-distilled competitive intelligence.
Buildlogs:
-
Programmatic SEO: 1,000 Pages From Supabase — Generating location and category pages from a database. The architecture, the edge cases, and the indexing timeline.
-
SEO Audit Automation: 13 Phases — A PRD-driven audit that runs 13 phases across technical, content, and competitive dimensions. What automated, what required human judgment.
-
Single-Page Calendar to SEO Engine — How a single-page event calendar became an SEO architecture with hundreds of indexable pages.
RevOps Analytics
The first generation of reporting skills was dangerously optimistic. Reported pipeline looked healthy. After adding zombie deal detection, forced-judgment sections, and a Pipeline Reality Check formula (reported minus zombies minus inflated equals real), the actual number was roughly half. Every deal flagged as zombie was confirmed dead on manual review. A four-minute skill now does what used to be a 30-minute manual pipeline review.
AI is great at generating reports. It's also great at generating reports that tell you what you want to hear. Building honest analytics meant adding gates that stop the report until someone signs off on the uncomfortable numbers.
Buildlogs:
-
Deal Health Check in 4 Min — A skill that runs a deal through zombie detection, evidence grading, and forced-judgment scoring. Four minutes instead of a 30-minute review.
-
AI for RevOps: The Complete Use-Case Map — Every RevOps use case I've found where AI actually works, versus where it sounds good but doesn't.
Paranoid CRM Operations
CRM is where I'm most conservative about automation. The cost of a bad write — merged contacts, lost activity history, corrupted pipeline data — is higher than the cost of doing it manually.
So: five matching layers for deduplication and zero automated writes. Every merge decision goes through human review. Every deletion batch starts with a canary, followed by monitoring pauses. Kill switches trigger on any protected record appearing in a delete set. The system does the analysis, surfaces the recommendations, and waits for a human to confirm. And yeah, back everything up first.
Buildlogs:
-
Paranoid CRM Operations: 5 Matching Layers — The matching architecture. Why five layers of deduplication still require human review, and the kill switch design that prevents catastrophic merges.
-
AI Prospect Research Agent — A research agent that queries CRM first, then enriches from external sources. The CRM-first principle and why it matters for data quality.
What This Is Not
This is not a pitch for any particular AI tool. The patterns work regardless of which model or interface you use. File-based state, formalized execution, codified institutional knowledge, knowledge graph architecture — these are architectural decisions that work in any editor, any model, any OS, and any vendor stack.
AI has not replaced people. The work still requires human judgment at every checkpoint. I review every brief before assembly begins. Every PRD has a BLOCKED_NEED_HUMAN signal for when the agent hits something it can't resolve. The AI handles the 80% that's execution. The human handles the 20% that's judgment.